04 óra¶
Tervezés¶
Tervezés folyamata¶
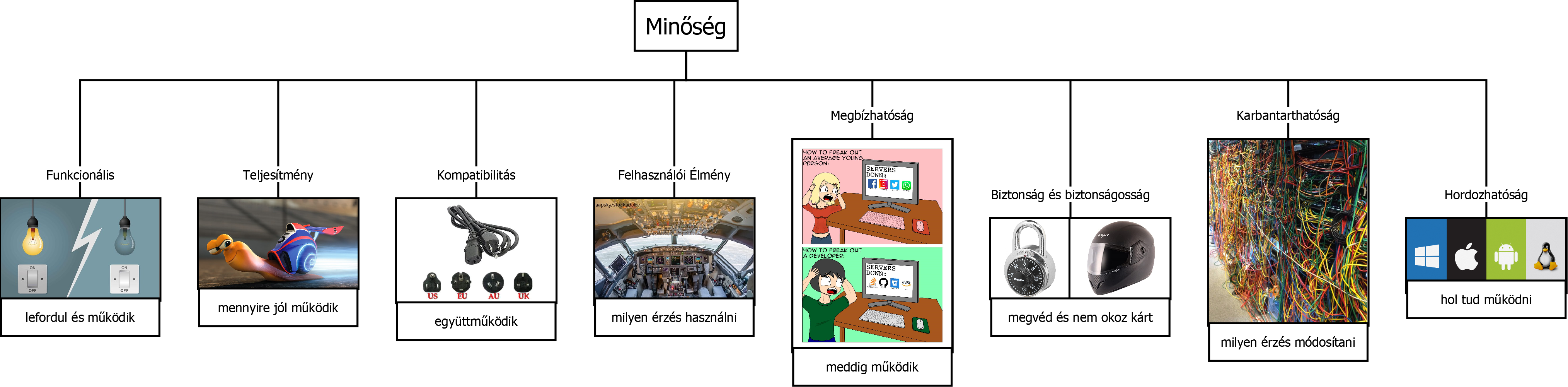
A tervezés célja, hogy a fejlesztő létrehozza a megvalósítandó szoftver azon modelljét, amely összhangban van az elérendő célokkal és figyelembe veszi az érintettek elvárásait, valamint a külöböző funkcionális, illetőleg nemfunkcionális követelményeket.
A tervezés különböző szinteken valósulhat meg. Jellemzően a magasabb absztrakciós szintből kiindulva készítjük az egyes terveket, amelyek fokozatosan közelítik azt a szintet, amelyen már az adott probléma valamely programozási nyelven is leírhatóvá válik. A tervezés granularitása tehát jelentősen függ attól is, hogy milyen eszközökkel végezzük el az implementációt.
A tervezés a követelmények elemzésével indul, azok finomításával, a használati esetek pontosításával és specifikálásával készül el a szoftver felhasználói szempontokat figyelembe vevő viselkedési modellje. A modellt kiegészíhetjük a folyamatokkal és az egyes komponensek közötti kommunikáció specifikálásával, amelyek már olyan granularitással rendelkeznek, hogy lehetőséget adnak az üzleti folyamatok implementálására.
Az üzleti folyamat
Az üzleti folyamat irányított, tervezett tevékenységek láncolata, amely egy adott cél elérése érdekében jött létre. Az üzleti életben három szinten definiálják őket, ez alapján lehetnek stratégiai, taktikai és operatív folyamatok.
A viselkedés alapú modellek önmagukban még nem lesznek implementációra alkalmasak. Meg kell tervezni azokat a komponenseket, amelyekhez a folyamatok, bemenetek és kimenetek, valamint különböző adatok rendelhetők. Ezek a komponensek képezik az architektúra tervek alapjait. Az architekturális tervezés is több szinten valósul meg, azonban itt lehetséges mind a felülről lefelé (top-down), mind az alulról felfelé (bottom-up) történő építkezés. Az első esetben nagyobb architekturális egységeket, komponenseket, csomagokat tervezünk, majd ezeket finomítjuk, míg a második esetben egyedi komponensek definíciójával (osztályok, objektumok) indulunk és szervezzük őket nagyobb csoportokba.
A tervezés alapelvei¶
- Vegyük figyelembe a lehetséges alternatívákat! Ne ragaszkodjunk egyetlen elképzeléshez!
- A terv kövesse az eredeti elemzési modellt! A viselkedés megtervezése során közvetlenül az érintettek által megfogalmazott követelményekből indulunk ki és a későbbiekben sem térünk el attól.
- Ne találjuk fel újból a kereket! Használjuk a bevált tervezési mintákat!
- A szoftver, amennyire lehetséges, kövesse a valós folyamatokat!
- A tervezés és az integráció során törekedjünk egységes szemléletre és keretekre!
- A tervezés során gondoljunk a lehetséges változásokra! Ne legyen a terv merev, a változásokat a lehető legkevesebb erőforrással kell tudni keresztülvezetni rajta.
- A nem várt helyzetek kezelését vegyük számításba, és adjunk elegáns megoldást rájuk!
- Ne keverjük a kódolást a tervezéssel! A két tevékenység eltér egymástól.
- Figyeljünk folyamatosan a minőségre!
- Nemcsak az implementációt, hanem a terveket is tesztelésnek kell alávetni.
- Törekedjünk a moduláris tervezésre! A moduláris architektúra könnyebben implementálható és karbantarható.
- A biztonság már a tervezés elején kiemelt szempont legyen! Mind az adatstruktúrák, mind a folyamatok és architektúrák tervezésénél tartsuk szem előtt az információ és a rendszer védelmét.
A szoftvert az ügyfélnek készítjük!
Folyamatosan tartsuk szem előtt, hogy a szoftvert nem magunknak, hanem az ügyfeleknek készítjük, az ügyféligények kielégítése céljából. Vegyük azt is figyelembe, hogy az ügyfeleken kívül további érintettek (stakeholderek) is vannak, és az ő elvárásaikat is figyelembe kell venni a fejlesztés során.
Adattervezés¶
Az adattervezés széles spektrumú tevékenység. Magába foglalja a bemeneti, kimeneti, és tárolt adatok tervezésének folyamatát. A tervezés során a legfontosabb feladat az adatféleségek összegyűjtése, csoportosítása, az entitások és az adattípusok meghatározása.
Mi a típus?
Az adatféleség lehetséges értékeinek halmaza, az ezeken végzett lehetséges műveletek, valamint megjelenítésük módja.
A tervezés során itt is figyelembe kell venni azt, hogy az implementáció milyen keretrendszerben valósul meg. Az olyan keretrendszerekben, mint a Spring magukat az adatokat is objektum orientált szemléletben tervezzük, azaz az entitásokhoz osztályokat rendelünk, amelyek tulajdonságai a specifikált adatoknak felelnek meg. Az ilyen keretrendszerben beépítve találunk olyan mechanizmusokat, amelyek segítségével az entitásként definiált osztályok leképezése valamely alkalmas adatbáziskezelő rendszerre automatikusan megtörténik. Ehhez a leképezéshez a fejlesztőnek a használt adatbáziskezelő rendszertől függően további információkat is meg kell adnia (kulcsok, kapcsolatok, stb.), de a leképezés módja konfigurálható.
Mi az adatosztály?
Az adatosztály olyan osztály, amely csak adattagokat (tulajdonságokat), valamint az ezek elérését bizotsító elemi műveleteket (getter/setter) tartalmazza.
JPA
JPA (Java Persistent API vagy újabban Jakarta Persisten API) egy olyan interfész specifikáció, amely relációs adatbázisok kezeléséhez biztosít egységes felületet.
Hibernate
A Hibernate egy nyílt forráskódú objektum relációs leképezést támogató keretrendszer, amely a JPA egy implementációját valósítja meg.
Az objektum orientált tervezés egyik nagy előnye az egységes szemlélet, valamint az, hogy nem választja szét az elemi típusok és az adatmodell tervezését, hanem természetes módon, egyetlen egységben végzi azokat.
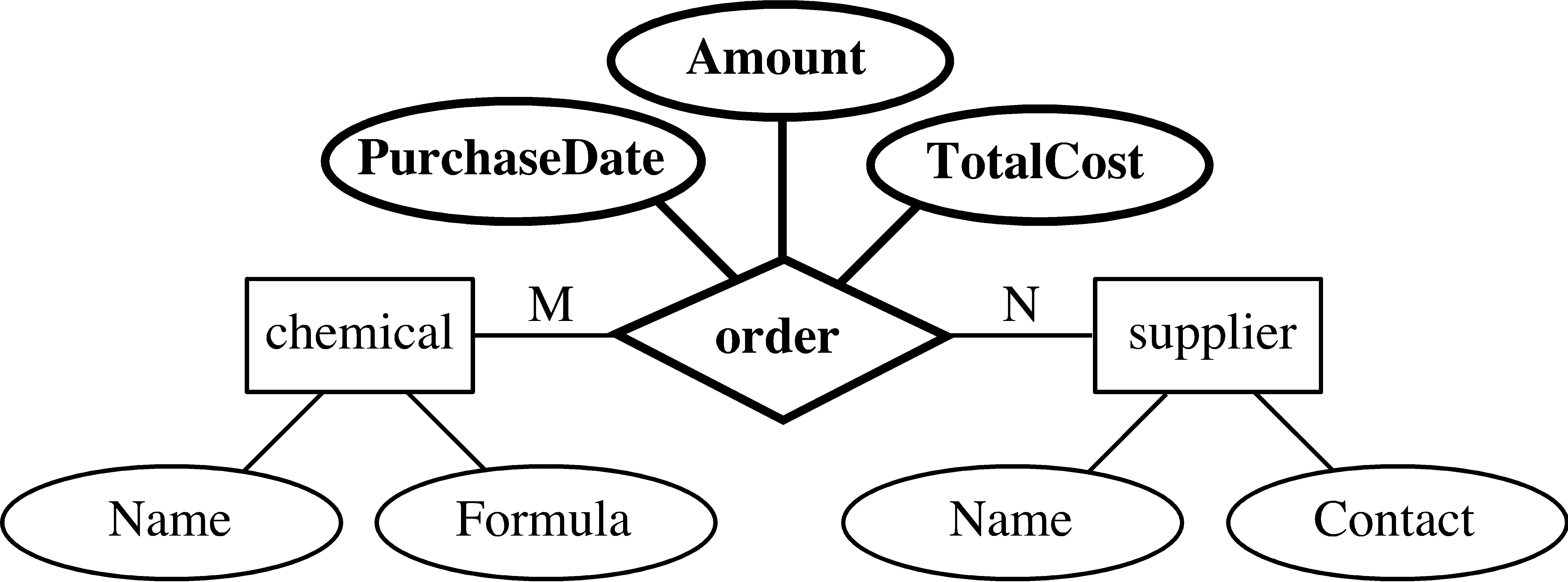
Az adatok tervezésének egy gyakran használt módszere az egyed kapcsolat modell, ami a fejlesztendő alkalmazáshoz tartozó adatbázis logikai modellje. Az EK modellek entitásokat és kapcsolatokat modelleznek, ahol az entitások és a kapcsolatok különböző attribútumokkal rendelkeznek.
Mi az entitás?
Az entitás olyan objektum, ami fizikailag (személy, autó, lakcím, stb.) vagy koncepcionálisan (vállalat, állás, kurzus, stb.) létezik. Ha az entitás léte nem függ más entitástól, akkor erős entitásról beszélünk, ellenkező esetben gyenge entitásról.
Mi a kapcsolat?
A kapcsolat az entitások közötti relációt fejez ki. Az egyed-kapcsolat modellben minden kapcsolatnak van számossága. A kapcsolatok számossága lehet egy az egyhez (1:1), vagyis egy entitás pontosan egy másik entitással áll relációban, egy a sokhoz (1:N), mikor egy entitás több másik entitással is kapcsolatban áll, valamint sok a sokhoz (N:M) kapcsolat, mikor N különböző entitás M másik entitással áll kapcsolatban.
Mi az attribútum?
Az attribútumok olyan jellemzők, amelyek meghatározzák az entitást, illetőleg részletezik a kapcsolatot. Ezek közül kiemelkedik a kulcs attribútum, amely egyértelműen azonosítja az entitást.
Adatbázis kiválasztása¶
Az alkalmazásunkban az adatbázist modellezhetjük osztályokkal. A fizikai tárolás módjáról ettől függetlenül döntést kell hoznunk. A megfelelő adatbáziskezelő rendszer választásához fel kell tennünk a következő kérdéseket:
- Milyen típusú adatokat tárolunk jellemzően?
- Mekkora a várható számosság?
- Írás vagy inkább olvasás történik-e gyakrabban?
- Az entitásokra vagy a kapcsolatokra helyezzük inkább a fókuszt?
Relációs adatbázisok: Olyan adatbázisok, amelyek a relációs adatmodellre épülnek. Ezekben az adatbázisokban az adatokat táblákban tároljuk. Az oszlopokat adattípusok (mezők) alkotják, a sorok a rekordok, amelyek a reláció elemeit jelentik. Az ilyen adatbáziskezelők tartalmaznak nézeteket, amelyek állandósított lekérdezésnek tekinthetők. Az indexek a táblákhoz kapcsolódnak és gyorsított keresést tesznek lehetővé. A kényszerekkel az adatok halmazára nézve tehetünk megszorításokat (pl. NOT NULL). A tábla elsődleges kulcsát is tekinthetjük egyfajta kényszernek.
Mi a reláció?
A reláció () az halmazok Descartes szorzatának egy részhalmaza (). A Descartes szorzat tényezőit alkotó halmazokat jelen esetben a táblák mezőiben adott adattípusok értékkészlete adja. A reláció egy eleme a tábla egy rekordja lesz.
Az elmélet és gyakorlat nem mindig ugyanaz!
A reláció egy halmaz (Descartes szorzat elem n-eseinek részhalmaza), ezért minden eleme egyedi. Az adatbáziskezelők azonban megengedik (amennyiben nincs megszorítás) ugyanazon elemek többszöri tárolását a táblában.
A relációs adatbázisok nyelve az SQL (Structured Query Language), tipikus képviselői az Oracle Database, MySQL, PostgreSQL, MSSQL, SQLite. A relációs adatbázisokhoz gyakorlatilag minden programnyelvhez találhatók libraryk, amelyek segítségével azok kezelését a programokban meg tudjuk oldani.
Vannak olyan esetek, mikor a relációs adatbáziskezelők nem nyújtanak kellően hatékony megoldást. Ilyen esetkeben célszerű az un. NoSQL adatbázisokat választani. Példul big data, dokumentumok, multimédiás adatok vagy gráf jellegű struktúrák tárolása esetén érdemes megfontolni ezeknek a használatát.
Dokumentum alapú adatbázisok: Olyan adatbázisok, amelyek dokumentum formájában tárolják az adatokat. Ezek a dokumentumok XML (Extensible Markup Language) vagy JSON (JavaScript Object Notation) formátumban adottak és lehetővé teszik a hiearchikus adatok tárolását is. Ilyen adatbáziskezelők a MongoDB, az Elasticsearch és a Document DB.
Gráf alapú adatbázisok: Már az 1960-as években is felvetődött ezeknek az adatbázisoknak a használata, de népszerűségük az elmúlt években vált jelentőssé. A gráf alapú adatbázisok különösen alkalmasak olyan struktúrák tárolására, ahol a kapcsolatok típusára kell szűrést végezni. Ilyen adatbáziskezelő a Neo4J, az Influx és a HyperGraphDB.
Big data: A Big Data megnevezést eredetileg olyan adatkészlet jelölésére használják, amely nagy méretű és komplex annyira, hogy a hagyományos adatkezelési eljárásokkal nem kezelhetők hatékonyan. Ezeket az adatbázisokat jellemzően elosztott módon tárolják és speciális (MapReduce) műveleteket alkalmaznak az adatkezelésre. Big Data-ra épülő adatbáziskezelők a következők AWS DynamoDB, Azure CosmosDB, Google BigQuery.
Tervezési eszközök¶
UML¶
Az objektum orientált tervezéshez az UML (Unified Modeling Language) eszköz átfogó támogatást nyújt mind a viselkedés alapú, mind az architekturális modellek elkészítéséhez. Az UML-ről, annak elterjedtsége és fontossága miatt külön oldalon olvashatunk jelen tananyag mellékleteként.
BPMN¶
A BPMN üzleti folyamatok modellezéséhez széles körben használt modell. Nem része az UML-nek, hanem önálló szabvány, amelyet a Business Process Management Initiative (BPMI) fejlesztett és az Object Management Group (OMG) tart karban. A modellt sz ISO is ratifikálta, ISO 19510 néven.
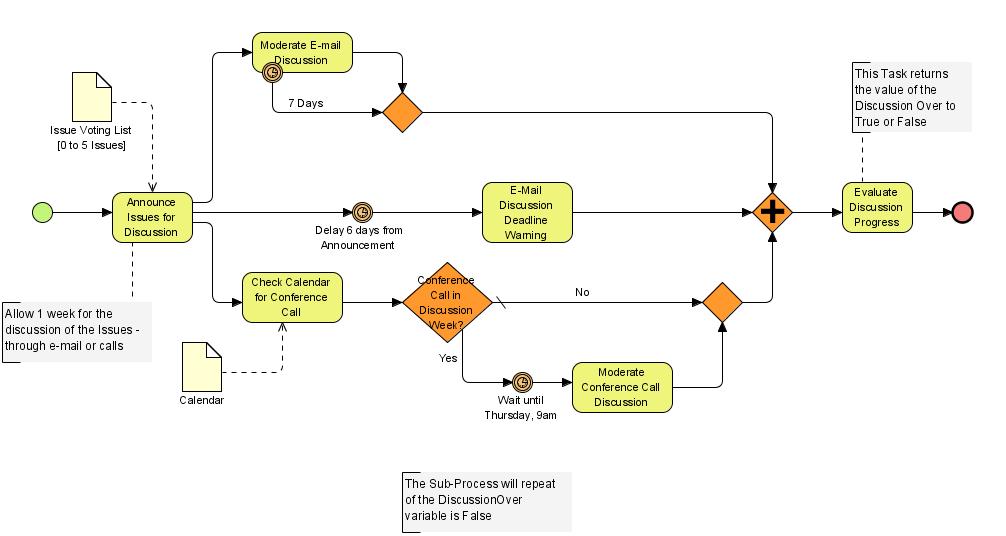
A modellt gyakran használják a rendszerszervezők, a use case diagramokkal együtt igen elterjedt az üzleti modellezésben.
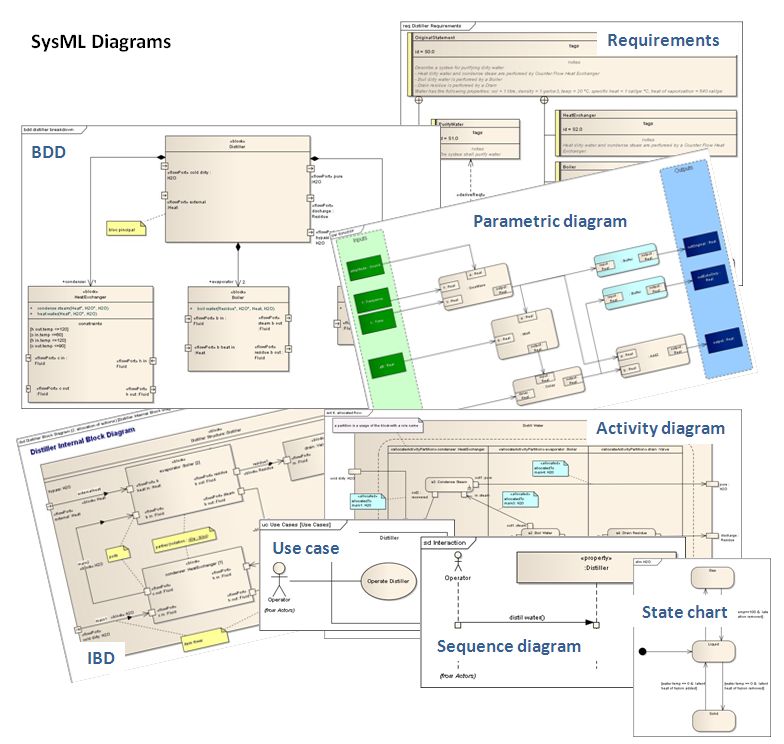
SysML¶
A SysML (System MOdeling Language) általános célú, mérnöki rendszerek modellezésére használt eszköz. Nem része az UML-nek, de használja annak diagramjait és annál flexibilisebb leírást biztosít az ipari rendszerek modellezéséhez.
9 diagramtípust tartalmaz:
- Blokk definíciós diagram
- Belső blokkdiagram
- Csomagdiagram
- Használati eset diagram
- Követelmény diagram
- Aktivitás diagram
- Szekvencia diagram
- Állapotgép diagram
- Paraméter diagram
 :
:
Szoftverek¶
A modellezéshez számos szoftvert lehet találni a világhálón az egyszerű rajzoló tooloktól kezdve egészen a kódgenerálást támogató komplex modellező eszközökig. Ezekről a szoftverekről egy listát találhatunk ezen a linken. Az egyszerűbb rajzoló toolok között több nyílt forráskódú, ingyenes eszközt is találunk, azonban a komplexebb támogatást nyújtó eszközök jellemzően nem ingyenesek. Egy-egy fejlesztő cég elérhetővé tesz ezek között a szoftverek között is olyan community-edition változatot, amelyek jól használhatók tanulásra és ingyenesen elérhetők, de ezek jellemzően csökkentett funkcionalitású termékek és kereskedelmi célú fejlesztésekhez nem használhatók. A tanuláshoz például a Visual Paradigm Community Edition használható, de ebben a szoftververzióban a reverse engineering funkció, illetőleg a kódgenerálás nem elérhető. Ezeknek a fejletteb funkcióknak a kipróbálására érdemes a korlátozott ideig, kipróbálásra szánt verziókat használni.
Az elérhető eszközök között nemcsak letölthető, hanem online toolok használatára is lehetőség van. A már említett Visual Paradigm szoftvernek is létezik online változata, amely számos lehetőséget kínál az előfizetőknek, de korlátozottan ingyenesen is használható. Amennyiben csak rajzolni szeretnénk, úgy a draw.io használatát javasoljuk, ahol az elkészült anyagot közvetlenül tudjuk menteni felhőtárhelyre (Google Drive, OneDrive, Dropbox, GitHub, GitLab) és az eszközünkre is. A tool lehetőséget ad kép formájában történő exportálásra, szép ábrák készíthetők a segítségével.
Issuek megértése¶
Az issuek megértéséhez elsősorban az szükséges, hogy a benne foglalt feladatot felhasználói oldalról megértsük. Ebben a folyamatban a megrendelő tud számunkra felvilágosítással szolgálni, hiszen ő az, aki az issue-ban foglalt követelmények birtokában van. Nem szabad azonban arról sem megfeledkezni, hogy az üzleti oldalon jelenlévő látens tudás nem minden esetben kerül tisztán megfogalmazásra. Az üzleti elemzők a követelmények tisztázásában, az egyes érintettek (stakeholderek) azonosításában és szempontjaik figyelembe vételében fontos szerepet játszanak.
A követelmények (mind a funkcionális és nemfunkcionális követelmények) tisztázását követően elkészült és megfogalmazott user story-k, illetőleg használati esetek szilárd alapot adnak a funkcionalitás megértéséhez. A fentiekben említett módon ettől kezdve a részletes viselkedés, valamint a résztvevő objektumok azonosítása már a tervezés feladata lesz.
Napjainkban már ritka a zöldmezős szoftverfejlesztés, gyakran egy meglévő szoftver fejlesztésébe kell bekapcsolódnunk. Ilyen esetben rendkívül fontos a issue által érintett szoftverelemek azonosítása és azok kapcsolatainak feltérképezése. Ebben a dokumentáció, illetőleg maga a programkód is segítséget nyújt (már amennyiben nem obfuszkált és megfelelő módon használják a nevezéktant). Amennyiben sikerült azonosítani a centrális objektumot, azok kapcsolatainak feltérképezésével megérthetjük, hogy az issue-ban megfogalmazottaknak megfelelően tervezett változások miként érintik a kapcsolódó osztályokat.
Visszatervezés
A visszatervezés (reverse engineering) az a folyamat, mikor egy adott modellből (pl. a forráskódból vagy a binárisból) egy magasabb absztrakciós szinten lévő, az eredeti modellel ekvivalens modellt hozunk létre. A magasabb absztrakciós szinten lévő modell közelebb van az emberi gondolkodáshoz, így jelentős támogatást adhat az adott rendszer megértéséhez.
Visszatervezést támogató toolok
A Visual Paradigm, Enterprise Architect és számos más szoftvereszköz fizetős változatai támogatják a forráskódból történő visszatervezést, amelynek során UML diagramokat készítenek a meglévő forráskódból. Ingyenes szoftvert a tananyag készítői nem találtak ebben a körben, a gyakorlaton viszont a Visual Paradigm kipróbálására szánt 30 napos próbaverziói segítségével a hallgatók megismerkedhetnek ezekkel a képességekkel is.
Függőségek feltérképezése¶
A visszatervezés során az erre alkalmas eszközök elkészítik az adott szoftver valamely magas szintű modelljét. Ilyen eszközök viszont nem mindig állnak rendelkezésre, ezért tekintsük át azokat a lépéseket, amelyek segítenek egy magas szintű modell manuális elkészítésében.
Mikor kiválasztod a módosítani kíván osztályt, jegyezd fel annak adattagjait és metódusait. Legjobb, ha ebben a folyamatban már közvetlenül UML ábrát készítesz, azt ugyanis könnyebb áttekinteni.
A következő lépésben a közvetlen kapcsolatok azonosítását kell elvégeznünk. Az objektum orientált rendszerekben ezek a kapcsolatok lehetnek:
- specializáció, általánosítás (azaz öröklés),
- implementáció (interfész),
- aggregáció, kompozíció,
- asszociációs kapcsolatok.
Az öröklési kapcsolatok felderítése során a szülőosztály, illetőleg az implementált interfész azonosítása a legkönnyebb lépés, ugyanis ez az osztály definícióját tartalmazó programsorból könnyen kiolvasható (extends illetőleg implements kulcsszó a szignatúrában). A gyermekosztály esetében ugyanezt a szignatúra elemet keressük a saját osztályunk nevével. Például ha az osztályunk neve JCall, akkor a fejlesztőeszközünk keresőjének segítségével keressünk rá az extends JCall kifejezésre, de ha a kereső támogatja a reguláris kifejezések használatát, akkor extends\s+JCall kifejezéssel a whitespacek sem fognak ki rajtunk. Hasonlóképpen járunk el, amennyiben interfészt módosítunk és annak implementációját keressük a programkódban (implements\s+JInterface).
Külön figyelmet érdemelnek a kivételosztályok. Ezek ugyanis több helyen előfordulhatnak és hajlamosak vagyunk megfeledkezni róluk. Két fontos programszakaszban fordulhatnak elő, egyrészt ahol a kivételt dobjuk (throw), másrészt ott, ahol ennek kezelését végezzük (except). Mindkét esetben a kivételosztály nevének keresésével találhatunk rá a kapcsolódó komponensekre.
Az aggregációs és kompozíciós kapcsolatok azonosításának kulcsa az, hogy az ilyen kapcsolatok tükröződnek az érintett oszzályok adattagjaiban úgy, hogy amennyiben a mi általunk módosított osztály a tartalmazott osztály, a kapcsolódó osztály érintett adattagjainak típusa az éppen módosítás alatt lévő osztály lesz. Ebben az esetben az osztály nevévenek keresésével megtalálhatók a kapcsolódó osztályok. A fordított irányban, azaz abban az esetben, amikor a módosítás alatt lévő a tartalmazó osztály az osztály nem primitív típussal rendelkező adattagjait kell megvizsgálni és megkeresni közöttük azokat, amelyek más osztályok azonosítói alapján lettek deklarálva.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
motor.inditas(); metódushívás az, ami figyelmet érdemel. Ilyen esetben már az adattag az, ami a kapcsolatot képviseli.
Aggregáció vs. kompozíció
Az aggregáció olyan kapcsolatot feltételez, amelyben a tartalmazott objektum a tartalmazó objektumtól függetlenül létezhet. Ilyen esetben a tartalmazó objektum csak referenciát tárol és a tartalmazott objektum kívülről kerül átadásra neki (jellemzően a konstruktoron keresztül). A kompozíció olyan kapcsolatot alakít ki, ahol a tartalmazott objektum nem létezhet függetlenül a tartalmazó objektumtól. Ilyen esetben a tartalmazott objektum a tartalmazó objektumon belül kerül példányosításra.
Az aggregációs és kompozíciós kapcsolatok komplexek is lehetnek!
A kapcsolatok feltérképezésénél a típus csak az érintett osztályok megtalálásában segít. A konkrét kapcsolatok a metódusokban vannak elrejtve, ahol a kapcsolatot az adott osztály adattagja fogja jelölni.
Az asszociációs kapcsolatok metódushívásokon keresztül valósulnak meg. Ezekben az esetekben nincs struktúrális kapcsolat, így a kapcsolatok a metódusok paraméterezése útján azonosíthatók. Nevezetesen itt is a típus fogja jelölni, hogy egy érintett metódus adott paramétere valamely más osztály objektumára mutató referencia lesz. Ebben az esetben a metódusok paraméterlistájában lévő típusok között kell megvizsgálni, hogy az érintett nem primitív típus valamely más osztály azonosítója-e, vagy sem.
Metóduson belül ideiglenesen példányosított osztályok!
Nem túl elegáns megoldás, de előfordulhat az is, hogy adott metóduson belül deklarálunk és példányosítunk objektumot. A kapcsolatok keresése során ezekről az esetekről se feledkezzünk meg, mi azonban kerüljük el az ilyen konstrukciókat!
Gondoljunk a tranzitív kapcsolatokra is!
A kapcsolatok feltérképezése, különösen nagyobb rendszer esetében nem triviális folyamat. A közvetlen kapcsolatok a fent ismertetett módon megtalálhatók, de a módosításunk során nemcsak a közvetlen, hanem a tranzitív kapcsolatok is érintettek lehetnek. Amennyiben a kapcsolódó osztályt is érinti a változás, úgy annak változásával további, a hozzá kapcsolódó osztályokat is vizsgálni kell. Ugyanakkor az is előfordulhat, hogy a közvetlen kapcsolódó osztályt nem szükséges módosítani, de egy hozzá kapcsolódó osztályt igen, amennyiben az adott kapcsolatban a közvetlenül kapcsolódó osztály közvetítő szerepet tölt be. Az ilyen gyakorlat alkalmazása kerülendő, de gondolni kell ezekre az esetekre is.
Statikus osztályok!
Statikus osztályokra mutató referencia metódustörzseken belül is előfordulhat, ezért a metódusokon belüli típusmegjelölésnél is keresni kell a lehetséges kapcsolatokat.
Az osztálykapcsolatok feltérképezésén túl a csomagok közötti függőségek megadására is szükség lehet. Amennyiben az osztályok közötti kapcsolatok ismertek, akkor a csomagok közötti függőségek már ezekből származtathatók. Külön figyelmet a csomagok kezelése akkor érdemel, amennyiben a módosításunk során egy 3rd party csomag valamely verzióját cseréljük le újabb verzióra. Ilyen esetben meg kell nézni (egyszerű keresésésel), hogy az érintett csomag használatban van-e más osztályban, és amennyiben igen, úgy azt is, hogy az újabb verzióra történő csere érinti-e az adottt komponens használt metódusát (például átnevezik, vagy megváltozik a paraméterlista, stb.).
Regressziós tesztelés
A módosítások elvégzése során folyamatosan hajtsunk végre regressziós teszteket (előfordulhat, hogy magukat a tesztesetet is módosítani kell). Bármilyen precízek is vagyunk, tévedhetünk. Ha figyelemen kívül hagytunk egy kapcsolatot, annak érintettsége esetén a regressziós tesztek várhatóan elbuknak.
Nemcsak a forráskód...
A kapcsolódó komponensek keresése során ne feledkezzünk meg a módosítással érintett komponensek dokumentációiról sem!
Folyamatrészletek meghatározása¶
Miután ismerjük a kapcsolódó komponenseket és rendelkezésünkre áll egy modell, fontos feladat annak megértése, hogy az egyes, általunk a módosítással érintett folyamatok miként működnek, miként érinti őket az általunk tervezett módosítás. Jelen szakaszban egy rövid példán mutatjuk meg, hogy milyen lépéseket kell tenni annak érdekében, hogy az érintett folyamatokat biztonságosan azonosítani tudjuk.
Vegyük példának a CodeMetropolis converter modulját! Ennek a modulnak a belépési pontja a toolchain/converter/src/main/java/codemetropolis/toolchain/converter/Main.java forrásfájlban található. A belépési pontot egy Java programban abban a forrásfájlban találjuk meg, amely a main metódust tartalmazza. A Java forrásfájlok névkonvenció szerint a bennük definiált osztály nevét veszik fel, valamint a main metódust tartalmazó osztály is gyakran (de nem mindig) Main néven van definiálva.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 | |
A fenti példában látjuk, hogy belépést követően a következő lépések történnek:
- A metódus első lépésben egy loggert definiál.
- Ezt követően példányosít egy objektumot, amely egy helper (
CommandLineOption) objektum és célja a parancsorban lévő opciók alapján a parancssori argumentumok értékei elérésének biztosítása, azok funkciója szerinti keresésel. A konkrét elemeket a parser tölti fel. -
A következő lépésben definiál egy parancssori értelmezőt. Ez az értelmező a
mainfüggvényünk paraméterében lévőargstömbben megadott értékeket értelmezi és tölti fel a helper objektumba. Tudjuk, hogy a CodeMetropolis moduljai parancssorban indíthatók és kötelezően tartalmaznak kapcsolókkal megadott opciókat. Ezek az opciók amainfüggvény paraméterében lévőargstömbbe kerülnek beStringtípusként. Ha hibásan adtuk meg az inputot, akkor ezen a szakaszon kivételdobás jön létre, amelyet acatchágak kezelünk le.-p paraméterek
A kapcsolók között kitüntetett szerepe van a -p kapcsolónak. Ezzel további paramétereket specifikálunk, amelyeket a programnak értelmeznie kell. A programkód ezekre a
paramsváltozóval hivatkozik megkülönböztetve a parancssori opcióktól. -
Ha sikeres az opciók értelmezése, akkor a folyamat egy a konverzió típusát definiáló opciótól (sourcemeter vagy sonarqube) függő
ConverterTypeobjektumot példányosít, amely a konverziós folyamathoz szükséges. A konverzióban alkalmazott lépések függenek attól, hogy milyen inputot adunk meg (sourcemeter, sonarqube). - Az ezt követő lépésben a -p kapcsolóval megadott paramétereket helyezi el a program egy
HashMapobjektumban. - Ha az opciók között szerepel a -h kapcsoló, akkor program ezen a ponton jeleníti meg a help szöveget.
- Az utolsó blokkban zajlik le a tényleges konverzió, amelyhez a program egy executor objektumot példányosít. Az executor hajtja végre a tulajdonképpeni konverziós lépéseket, amelyben a konvertrter típus objektumot, az inputot, a kimeneti fájl nevét és az előző lépésben definiált paramétereket tartalmazó HashMapet kapja meg paraméterként.
Demonstrációs példa¶
A Make The Mapping Seriazable issue-t demonstrációs célra hoztuk létre. Az issue azt kéri, hogy tegyük lehetővé a CodeMetropolis Mapping osztályának szerializálását. A leírás szerint:
Make the Mapping class serializable and demonstrate the results using the corresponding tests.
A leírás nem sok információt közöl, csak éppen a szükségeseket:
- a
Mappingosztályt érinti, - szerializálást kell lehetővé tenni az osztályban.
Az implementáció előtt az osztály felépítését és kapcsolatait elemezni kell.
A Mapping osztályt a toolchain/mapping/src/main/java/codemetropolis/toolchain/mapping/model útvonalon találjuk a Mapping.java forrásban. Mivel a kapcsolatokat is fel szeretnénk térképezni, ezért a model könyvtár osztályait is megrajzoljuk, illetőleg reverse engineering tool segítségével elkészíthetjük.
Kapcsolatok ábrázolása
A hallgatói projektek esetén nem kell kiterjedt UML ábrát rajzolni, de a közvetlen kapcsolatokat minden esetben ábrázolni kell.
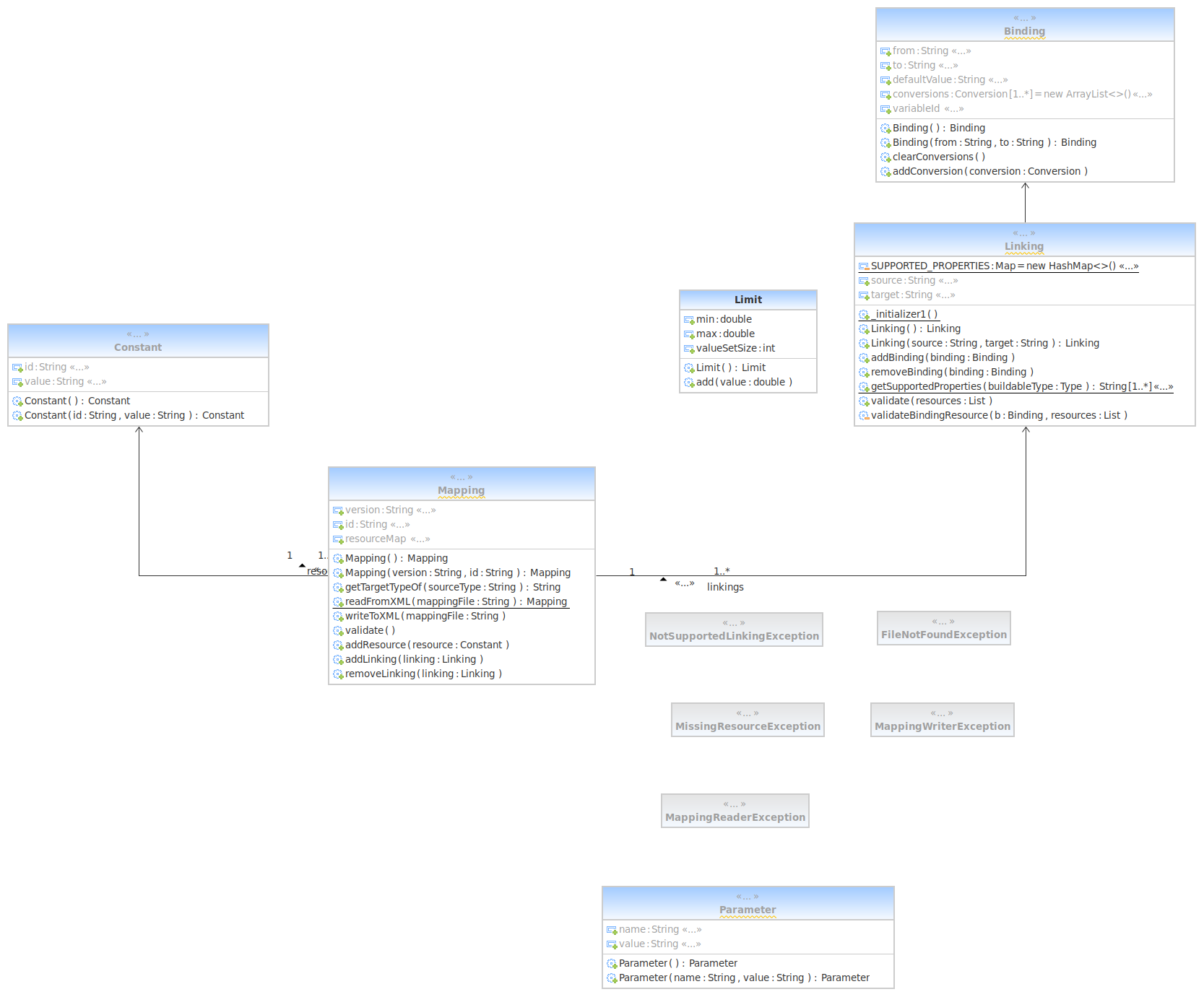
Az ábráról egyből leolvasható, hogy a feladat korrekt végrehajtásához nem elegendő pusztán a Mapping szerializációjáról gondoskodni, hanem a lista elemek osztályainak szerializációját is biztosítani kell. Ezek a Constant és a Linking osztályok által vannak megvalósítva. Hovatovább a Linking osztály kapcsolatban áll a Binding osztállyal, amelyet teljes szerializáció esetén szintén szerializálnunk kell. Alapos elemzés nélkül valószínűleg ezeknek az osztályoknak a szerializációját kihagytuk volna.
Megjegyzés a példához
A demoban a kollekciók tartalma külön nem lesz szerializálva, de az érintett osztályokat is meg fogjuk jelölni. Ez azt jelenti, hogy a Mapping osztályon belül a kollekciók tartalmára lesz hivatkozás, azonban azok üres objektumok lesznek. Ahhoz, hogy teljes tartalom szerializálva legyen, minden érintett osztály tartalmát ki kell írni a háttértárra. A demonstrációban erre nem kerül sor.
Szerializáció
A szerializáció olyan mechanizmus, amely az adott objektum aktuális állapotát menti sorosítható tárhelyre. Ahhoz, hogy egy objektum szerializálható legyen implementálni kell neki a java.io.Serializable interfészt. Az érintett objektum minden mezőjének szerializálhatónak kell lenni, a nem szerializálandó mezőket a transient annotációval el kell látni.
A szerializációt közvetlenül az ObjectInputStream és ObjectOutputStream osztályokban implementált metódusok hajtják végre, a két műveletet (serializáció és deserializáció) célszerű külön osztályban elkészíteni.
Kiegészítés a példához¶
A fenti egyszerű példában is látható, hogy esetenként szükség lehet további, nem közvetlenül a forrásban található függőségek meghatározására és összegyűjtésére. Ilyen esetek:
- Külső modulok, csomagok: milyen packagekre van szükség, ezek mely verziói kompatibilisek a rendszeremmel? Szükséges-e újabb verziójú packaget használni és okoz-e a meglévő programban problémákat?
- Ahhoz, hogy az utóbbi kérdésre válaszoljunk, meg kell vizsgálni, hogy a felhasznált package-ben milyen osztályokat és metódusokat használ a rendszerünk és ezek érintettek-e a verzióváltással.
- Dokumentáció: egyrészt az érintett csomagok dokumentációit kell azonosítanunk és megvizsgálni, hogy a változások miként érintik, másrészt az általunk megvalósítandó funkcionalitást tartalmazó csomagok dokumentációit is figyelembe kell vennünk.
- A fenti példában a szerializáció dokumentálásából tudhatjuk azt, hogy egyrész mit kell implementálni, másrészt milyen implicit függőségek jelentkezhetnek (például a tartalmazott objektumok szerializálása).
Megbeszélés memok¶
A megbeszélések tartalmát jegyzőkönyvekbe kell foglalni. A jegyzőkönyvek hivatalos dokumentumok, amelyek egy adott megbeszélésen, előadáson vagy találkozón történt eseményeket rögzítik. Céljuk kettős. Egyrészt alátámasztják a szóban elhangzottakat, másrészt emlékeztetőül szolgálnak a résztvevők számára.
A jegyzőkönyvek helyett a projektmegbeszéléseken elegendő emlékeztetőt írni, amelynek célja hasonló, mint a jegyzőkönyvé, csak kevésbé formai. Ugyanakkor ezeknek is van egy kötelező tartalma, amelyet figyelembe kell vennünk.
Kötelező tartalmi elemek:
- A megbeszélés ideje
- A megbeszélés helyszíne (lehet online is, de jelölni kell az alkalmazott platformot)
- A megbeszélés résztvevői, küldő szervezet (ha van)
- A megbeszélés napirendi pontjai
- A napirendi pontokhoz kapcsolódóan elhangzottak tényszerűen megfogalmazva
- Cselekvési tervek, kijelölt felelősök és határidők
- A memo készítőjének neve, titulusa, elérhetősége
Moderálás
Egy megbeszélés gyakran kötetlen formában zajlik és sokszor követhetetlen, amennyiben a résztvevők nem várják meg a másikat és egymás szavába vágnak. Ilyenkor memót írni képtelenség. Fontos ezért, hogy minden megbeszélés kijelölt mederben follyon, előre tervezett kezdete és vége legyen, illetőleg legyen egy moderátora, aki felelős azért, hogy egyszerre csak egy résztvevő beszéljen, és minden résztvevő ki tudja fejteni a véleményét. Az is megoldás lehet, ha felvételt készítünk a megbeszélésről, ezt azonban csak akkor tegyük, ha minden résztvevő ehhez hozzájárulását adta.
Mit írjunk le?
Még abban az esetben is, ha jól struktúrált egy megbeszélés, kihívást jelenthet egy-egy résztvevő mondanivalójának rögzítése. A memo készítőjének azonban nem kell mindent lejegyeznie, csak azokat a megállapításokat, véleményeket, amelyek szorosan a tárgyhoz kapcsolódnak, illetőleg nem kell ezeket szó szerint idézni sem. Bizonytalanság esetén vissza lehet kérdezni. A memokat a résztvevők később átolvassák és jóváhagyják, ezért ha hibázunk, az sem jelent végzetes hibát.
A projektfeladathoz kapcsolódó memókat az issue alá, markdown formátumban kell elkészíteni és minden résztvevőnek ellenőrizni kell azt.