Objektumok tárolása
Általánosságban a programok új változókat, objektumokat általában olyan szempont alapján hoznak létre, ami sokszor csak futási időben derül ki. Előtte az is lehet, hogy az sem egyértelmű, hány változót kell létrehozni pontosan, vagy még az is lehet, hogy a változó típusa sem lesz egyértelmű.
A C nyelvben már megismertük a tömböket, amik alkalmasak arra a célra, hogy több, egyforma típussal rendelkező változót tároljanak el, de a Java függvénykönyvtárak lévén ennél sokkal több lehetőségünk adódik a különböző konténer osztályok által, amiket a java.util könyvtárban találunk.
Tömbök¶
Amikor döntünk, hogy a változóinkat milyen módon akarjuk tárolni, fontos azt tudnunk, hogy az egyes tárolási módoknak mik az előnyei, hátrányai. Tömbök esetében láttuk, hogy az a lehetőség, hogy az indexszeléssel könnyen el tudunk érni egy-egy elemet, hatékony lehet. Ugyanakkor az a tény, hogy a tömb létrehozásakor meg kell mondanunk annak a méretét lehet, nem minden esetben lesz praktikus.
Az Arrays osztály¶
Ha a tömbök használata mellett döntöttünk, akkor a java.util.Arrays osztály lehet számunkra nagy segítség, hisz számos olyan lehetőséget tartalmaz, ami a tömbelemek feldolgozását átvállalja helyettünk.
A tömbök vagy primitív típusokat, vagy referenciákat tartalmaznak. Ahhoz, hogy két tömb egyenlőségét ellenőrizni tudjuk, a tömbök méretének vizsgálata után egyesével kell összehasonlítani a tömb elemeit. Ezt akár azonban az equals metódus is megteszi helyettünk. A fill metódussal egy adott tömböt egy adott értékkel tudunk inicializálni, a sort metódus rendezi a tömb elemeit, a binarySearch metódus lehetőséget ad arra, hogy egy már rendezett tömbben hatékonyan keressünk meg egy konkrét elemet, illetve ezeken kívül számos olyan metódusa adott az Arrays osztálynak, ami megvalósítja a leghétköznapibb tömb műveleteket.
Tömbök egyenlősége, feltöltése¶
import java.util.*;
public class Tombok {
public static void main(String[] args) {
int[] a1 = new int[10];
int[] a2 = new int[10];
Arrays.fill(a1, 47);
Arrays.fill(a2, 47);
System.out.println(Arrays.equals(a1, a2));
}
}
A fenti példában adott két tömbünk, a1 és a2. Mind a kettő egészeket tárol, pontosan 10-et. Az Arrays.fill metódusa arról gondoskodik, hogy ez a 10 érték mind a két tömbben jelen esetben a 47 érték legyen. Ha csak az a1==a2 összehasonlítást néznénk, akkor hiába egyezik meg a két tömb méretre, tartalomra, a kifejezés értéke hamis lenne, hiszen itt az a1 és a2 változó hivatkozásokat hasonlítjuk össze, amik különböznek. Az Arrays.equals(a1, a2) azonban egyesével hasonlítja össze a tömb elemeit, és így jelen esetben true-val tér vissza.
Tömbök rendezése¶
Tömbök elemeinek rendezésekor minden esetben először azt kell definiálni, hogy a tömbben tárolt elemek között milyen rendezési reláció van, azaz két elemről el kell tudni dönteni, melyik a kisebb, vagy a nagyobb, esetleg egyenlőek-e. Természetesen a primitív típusoknál ez a rendezés adott, viszont objektumok esetében nem az, ezt valahogy definiálni kell.
Ha megadjuk a tömbelemek közötti rendezési relációt, akkor a rendezési algoritmusok a tömbben tárolt elemek típusától függetlenül is rendezni tudják a tömböt. Két megoldás létezik arra, hogyan tudjuk ezt a rendezési információt átadni a rendező algoritmusoknak. Az egyik a Comparable, a másik a Comparator interface implementálása. A rendező algoritmusok az ezekben definiált compareTo, vagy compare, illetve equals metódusok hívásával fogja callback módon összehasonlítani a tömbelemeket.
Az egyszerűbb talán a Comparable interface implementálása, ilyenkor az adott típust láthatjuk el a megfelelő compareTo metódussal, amelyel az osztály aktuális objektumát tudjuk összehasonlítani egy, a compareTo paraméterében kapott másik objektummal.
import java.util.*;
class Tancos implements Comparable {
double magassag;
public Tancos(double m) {
magassag = m;
}
public int compareTo(Object o) {
double masik = ((Tancos)o).magassag;
return (magassag < masik ? -1 : (magassag == masik ? 0 : 1));
}
public String toString() {
return String.format("%.2f", magassag) + " cm";
}
}
public class ComparablePelda {
static void print(Tancos[] t) {
for (int i = 0; i < t.length; i++)
System.out.println(t[i]);
System.out.println();
}
public static void main(String[] args) {
Tancos[] t = new Tancos[10];
for (int i = 0; i < t.length; i++)
t[i] = new Tancos(Math.random()*100+100);
print(t);
Arrays.sort(t);
print(t);
}
}
A példában a Tancos osztálynak van egy magassag attribútuma, ez lesz az, ami alapján két táncost szeretnénk összehasonlítani. Ha ez a két érték egyenlő, akkor két táncost egyformának tekintjük, egyébként pedig a magasság alapján mondjuk azt, hogy egyik kisebb/nagyobb a másiknál. A példában a Tancos osztály implementálja a Comparable interface-t, ennek hozománya, hogy az osztályban meg kell valósítani a compareTo metódust, ami paraméterében egy Object típusú paramétert vár. Mivel mi ezt a compareTo-t csak a tömbelemek összehasonlítására alkalmazzuk csak, így tudjuk, hogy a compareTo meghívásakor ez a paraméter csak Tancos típusú lehet. Ennek megfelelően kasztolhatjuk az Object paramétert Tancos típusúvá. Az aktuális objektum és a paraméter magasság attribútumának összehasonlítása után a compareTo visszatérési értéke 0, ha a két magasság érték egyenlő, -1 (azaz negatív), ha az aktuális táncos a kisebb, és +1 (azaz pozitív), ha az aktuális táncos a nagyobb.
A ComparablePelda osztályban teszteljük a módszerünket. Itt a main metódusban egy 10 táncost tartalmazó tömböt hozunk létre, amelyben a táncosokat random magasság értékkel inicializálunk, majd kiírjuk a tömb tartalmát, rendezzük azt az Arrays.sort metódusának meghivásával, majd újra kiírjuk a tartalmat. A kiíráskor a táncosok magasságára koncentrálunk, a print metódust ennek megfelelően írtuk meg. Mindezek után a ComparablePelda osztály futtatásakor kapott kimenetünk a következő:
Kimenet
130,75 cm
177,28 cm
125,79 cm
115,60 cm
114,43 cm
176,19 cm
170,01 cm
194,40 cm
139,45 cm
152,51 cm
114,43 cm
115,60 cm
125,79 cm
130,75 cm
139,45 cm
152,51 cm
170,01 cm
176,19 cm
177,28 cm
194,40 cm
Vannak helyzetek, amikor az nem megoldás, hogy a Comparable interface-t implementáljuk. Ez lehet akkor, ha az osztály, aminek objektumait el akarjuk tárolni, nem hozzáférhető, azaz nem tudunk beleírni, mert külső kód. De az is lehet, hogy több olyan adattag is van, amely alapján a rendezést meg szeretnénk valósítani, és a compareTo-ban ezt nem tudjuk megmondani, hogy mikor melyik rendezést szeretnénk választani. Vagy az is lehet, hogy az osztály már implementálta már a Comparable interface-t, de mi teljesen más módon szeretnénk az összehasonlítást elvégezni, viszont a compareTo átírása nyilván módosítaná a már meglévő kód működését. Ilyenkor használatjuk a Comparator interface-t, amivel egy összehasonlító osztályt tudunk létrehozni, amely két, a paraméterében kapott objektumot hasonlít össze.
Írjuk át az előző példát ezt használva:
import java.util.*;
class Tancos {
double magassag;
public Tancos(double m) {
magassag = m;
}
public String toString() {
return String.format("%.2f", magassag) + " cm";
}
}
class TancosComparator implements Comparator {
public int compare(Object o1, Object o2) {
double m1 = ((Tancos)o1).magassag;
double m2 = ((Tancos)o2).magassag;
return (m1 < m2 ? -1 : (m1 == m2 ? 0 : 1));
}
}
public class ComparatorPelda {
static void print(Tancos[] t) {
for (int i = 0; i < t.length; i++)
System.out.println(t[i]);
System.out.println();
}
public static void main(String[] args) {
Tancos[] t = new Tancos[10];
for (int i = 0; i < t.length; i++)
t[i] = new Tancos(Math.random()*100+100);
print(t);
Arrays.sort(t, new TancosComparator());
print(t);
}
}
A TancosComparator osztály lesz az összehasonlító osztályunk, amelyben a compare metódust kell implementáljuk. A main metódust annyival kell változtatnunk, hogy a rendezés során a rendezést megvalósító sort metódusnak meg kell adnunk ennek az összehasonlító osztálynak egy objektumát. A kimenete ennek a programnak hasonló lesz, mint az előző megoldásé.
Tömbben keresés¶
Miután rendeztünk egy tömböt, lehetőség van arra, hogy abban hatékonyan keressünk egy konkrét elemet az Arrays.binarySearch metódusával. Amennyiben ez a keresett elemet megtalálja, úgy egy pozitív értékkel tér vissza, ami az adott objektum tömbbeli indexe, egyébként a visszatérési érték negatív. Ha esetleg több elem is megfelel a keresésnek, akkor bizonytalan, hogy ez a metódus melyik elemet adja vissza. Amennyiben a tömböt egy Comparator objektum segítségével rendeztük, akkor ugyanezt az objektumot a binarySearchnek is át kell adni:
public class TombbenKereses {
public static void main(String[] args) {
int[] t = new int[100];
/* tömb feltöltése */
Arrays.sort(t);
/*...*/
int pozicio = Arrays.binarySearch(t, 19);
if (pozicio >= 0) {
/* megvan */
}
}
}
Tömbök másolása¶
Tömbök másolását bár elég könnyen meg tudjuk magunk is valósítani, a System.arraycopy metódusát felhasználhatjuk arra, hogy adott tömb, adott indexű elemétől egy másik tömb meghatározott indexű pozíciójától kezdve megadott számú elemet átmásoljunk:
public class TombokMasolasa {
public static void main(String[] args) {
int[] i = new int[25];
int[] j = new int[25];
/*...*/
System.arraycopy(i, 0, j, 0, i.length);
/*...*/
}
}
Természetesen arra azonban vigyázzunk, hogy a cél tömböt is megfelelően inicializáljuk, illetve csak a tömbök elemszámának megfelelő mennyiségű elemet másoljunk csak.
Kollekciók (konténerek)¶
A tömbök mellett a Java gondoskodik arról, hogy különböző egyéb módokon is el tudjuk tárolni nagy számú adatainkat. A ma már elég széleskörben, hatékonyan felhasználható konténer típusok azonban lassú fejlődés útján jutottak el a mostani állapotukig. A kezdeti megoldások annyira rosszul sikerültek, hogy teljesen újra kellett tervezni őket, illetve az áttervezés után is még nagyon sok nyelvi változást kellett bevezetni ahhoz, hogy az egészet hatékonyan lehessen használni.
Alapvetően két nagy koncepciója van a tároló típusoknak:
- Kollekció (Collection): Egyéni elemek csoportja, általában valamilyen szabályossággal (listában sorrendiség, halmazban egyediség, stb.)
- Leképezések (Map): Kulcs-adat kettősök csoportja, a kulcsra gyors keresést biztosítanak
Egy kis példa segítségével nézzük meg, hogyan is érték el ezek a tárolók a mai formájukat.
import java.util.*;
public class Kollekciok {
static Collection feltolt(Collection c) {
c.add("kutya");
c.add("macska");
c.add("macska");
return c;
}
static Map feltolt(Map m) {
m.put("kutya", "Odie");
m.put("macska", "Arlene");
m.put("macska", "Garfield");
return m;
}
public static void main(String[] args) {
System.out.println(feltolt(new ArrayList()));
System.out.println(feltolt(new HashSet()));
System.out.println(feltolt(new HashMap()));
}
}
A Kollekciok osztályban definiáltunk két statikus feltolt metódust, egyik egy Collectiont, a másik egy Mapet kap paraméterül, és mind a kettőben azt csináljuk, hogy ehhez a kapott tárolóhoz elemeket adunk hozzá a tárolónak megfelelően. Azaz a kollekcióba szimpla elemeket töltünk fel (a példában fontos, hogy ismétlődő elemek is vannak, ld. "macska"), míg a Map-be kulcs-érték párokat (itt is van ismétlődés a kulcsok között, bár ugyanahhoz a kulcshoz más-más érték tartozik most). A visszatérési értéke mindkét metódusnak legyen a már feltöltött tároló.
A Kollekciok osztály main metódusában különböző konkrét tárolókkal hívjuk meg a feltolt metódusokat, és a System.out.println metódussal írjuk ki a feltöltött tárolókat. A követlező kimeneteket kapjuk:
Kimenet
[kutya, macska, macska]
[kutya, macska]
(kutya=Odie, macska=Garfield)
Az első sor az ArrayList működését szemlélteti. Látszik, hogy nem gond az egyforma érték, a két macska elem, mindet beszúrja egymás után a tárolóba (ez a listákra jellemző megoldás). A HashSet már érzékeny az ismétlődésekre, ha egy elem már benne van a halmazba, az nem kerül újra be, így csak egy macska lesz végül a tárolóban. A HashMap sem tartja meg az összes ugyanolyan kulcsú elemet, az új előfordulása egy adott kulcsnak felülírja a régi elempárt.
A Java 5 előtti kollekciók hiányosságai¶
Ahogy arról szó volt, a kollekciók mai működése lassan alakult ki. A Java 5 előtti kollekciók még messze nem voltak annyira kényelmesen használhatóak. Ennek oka, hogy ekkor minden kollekció csak és kizárólag Object típust tudott fogadni, azaz általános célúak voltak, nem tárolhattak specifikus típusokat. Ez nyilván azért gond, mert így a programozónak hiába célja adott esetben az, hogy csak egy bizonyos típusú elemet tesz a tárólóba, nem feltételezheti, hogy az is kerül bele mindig. Amikor egy elem bekerül a tárolóba, akkor gyakorlatilag a referenciája tárolódik el benne (upcast), ha fel szeretnénk használni az eltárolt elemek egyéb tulajdonságait is, akkor ahhoz downcastolnunk kell a megfelelő típusra. Mivel azonban ezt biztonságosan csak úgy tehetnénk meg, hogy minden downcast előtt ellenőrizzük az adott elem típusát, ez meglehetősen macerás lesz. Viszont ha nem ellenőrizzük, könnyen járhatunk úgy, mint a következő példa:
import java.util.*;
class Kutya {
private int kutyaSz;
Kutya(int i) {kutyaSz = i;}
public void print() {
System.out.println(
"Kutya #" + kutyaSz);
}
}
class Macska {
private int macskaSz;
Macska(int i) {macskaSz = i;}
public void print() {
System.out.println(
"Macska #" + macskaSz);
}
}
public class KutyakEsMacskak {
public static void main(String[] args) {
ArrayList kutyak = new ArrayList();
for(int i = 0; i < 3; i++)
kutyak.add(new Kutya(i)); // upcast Object-re!!!
// nem problema berakni egy macskat a kutyak koze:
kutyak.add(new Macska(3)); // upcast Object-re!!!
for(int i = 0; i < kutyak.size(); i++) // downcast Kutya-ra!!!
((Kutya)kutyak.get(i)).print();
// futas kozbeni hiba a 4. iteracioban (kiveteldobas)
}
}
Ebben a programban adott egy Kutya és egy Macska osztály, mindkettőnek egy print metódusa, ami adott kutyus és macsesz jellemzőjét kiírja. A futtatható KutyakEsMacskak osztályban létrehozunk egy ArrayListet, és bár a tároló neve kutyak, ez megtévesztő lehet, mert ebbe ellenőrzés nélkül rakosgatunk kutyákat és macskákat (Nyilván bármelyik tároló ugyanígy viselkedik, a példában most az ArrayListet választottuk.) Addig nincs is probléma, amíg az elemeket csak rakosgatjuk a tárolóba. A baj akkor jelentkezik, amikor meg szeretnénk hívni a Kutyak osztály print metódusát. Amíg kutya objektumokat szedünk ki a tárolóból, nincs gond, ezeket downcastolhatjuk Kutya típusúvá, és már meg is hívhatjuk a Kutya osztályban definiált print metódust. A gond akkor lesz, amikor a macska objektumot próbáljuk kutyává alakítani. Ez nyilván nem lehetséges, ezért futás közbeni hiba jelentkezik, a programunk leáll.
Kimenet
Kutya #0
Kutya #1
Kutya #2
Exception in thread "main" java.lang.ClassCastException at KutyakEsMacskak.main(KutyakEsMacskak.java:27)
Hogyan tudnánk orvosolni ezt a problémát?! Egyfelől nyilván úgy, hogy minden konverzió előtt ellenőrizzük az adott objektum típusát, és a megfelelő típusra konvertálunk. Ez persze azon túl, hogy macerás beírni a kódba, lassítja is annak végrehajtását a plusz ellenőrzések miatt. Másfelől látjuk, hogy jelen esetben mind a két osztálynak, akinek objektumai bekerültek a tárolóba, van print metódusa, és a szándék az, hogy ezt meghívjuk. A legegyszerűbb az lenne, ha ezt a viselkedést kiemelnénk egy közös interface-be, és a konverziót erre az interface-re valósítanánk meg. Másfelől az Object osztály toString metódusa pont ezzel a céllal készült, így jelen esetben az is megoldás, hogy a Kutya és Macska osztályban felüldefiniáljuk az Object osztály toString metódusát, így még a konverziót is elkerülhetjük az adott interface típusra, ha a print helyett a toStringet használjuk:
import java.util.*;
class Kutya {
private int kutyaSz;
Kutya(int i) {kutyaSz = i;}
public String toString() {
return "Kutya #" + kutyaSz;
}
}
class Macska {
private int macskaSz;
Macska(int i) {macskaSz = i;}
public String toString() {
return "Macska #" + macskaSz;
}
}
public class KutyakEsMacskak2 {
public static void main(String[] args) {
ArrayList kutyak = new ArrayList();
for(int i = 0; i < 3; i++)
kutyak.add(new Kutya(i)); // upcast Object-re!!!
// nem problema berakni egy macskat a kutyak koze:
kutyak.add(new Macska(3)); // upcast Object-re!!!
for(int i = 0; i < kutyak.size(); i++)
System.out.println(kutyak.get(i));
}
}
Ekkor a program szépen lefut az alábbi kimenettel:
Kimenet
Kutya #0
Kutya #1
Kutya #2
Macska #3
Típust megőrző kollekciók készítése¶
Az előbbi probléma megoldása lehet az is, ha valahogy ellenőrizzük már a konténerbe való bekerüléskor, hogy abba tényleg csak megadott típusú elemek kerülhessenek be. Ekkor ha bármelyik elemet kivesszük, biztosak lehetünk annak típusába, és az adott típusra történő konverzió nem okozhat hibát. Ezt első körben úgy érhettük el, hogy adott típusra megírtunk egy külön tároló osztályt, ami ezt az ellenőrzést megtette:
import java.util.*;
class Kutya {
private int kutyaSz;
Kutya(int i) {kutyaSz = i;}
public String toString() {
return "Kutya #" + kutyaSz;
}
}
class KutyaLista {
private ArrayList lista = new ArrayList();
public void add(Kutya k) {
lista.add(k);
}
public Kutya get(int index) {
return (Kutya)lista.get(index);
}
public int size() {return lista.size();}
}
public class KutyaListaTeszt {
public static void main(String[] args) {
KutyaLista kutyak = new KutyaLista();
for(int i = 0; i < 3; i++)
kutyak.add(new Kutya(i)); // nincs upcast!
//kutyak.add(new Macska(3)); // forditasi hiba
for(int i = 0; i < kutyak.size(); i++)
System.out.println(kutyak.get(i)); // nem kell downcast!
}
}
Itt a KutyaLista osztály az, ami gyakorlatilag egy ArrayList becsomagolása. Az add és get metódusok lehetővé teszik, hogy csak Kutya objektum kerüljön be a tárolóba, illetve kivételkor Object helyett már eleve Kutyára konvertálva kapjuk vissza az ArrayListben Object-ként eltárolt elemet.
Ha a KutyaListaTeszt main metódusában a KutyaLista tárolóhoz megpróbálnánk egy más, pl. Macska objektumot hozzáadni a KutyaLista tárolóhoz (ld. 27. sor), ez fordítási hibához vezetne, mert az add metódus egyértelműen Kutya objektumot vár.
A három kutya hozzáadásával és kiolvasásával ennek a programnak a kimenete az alábbiak szerint alakul:
Kimenet
Kutya #0
Kutya #1
Kutya #2
A KutyaLista UML diagramja a következő:
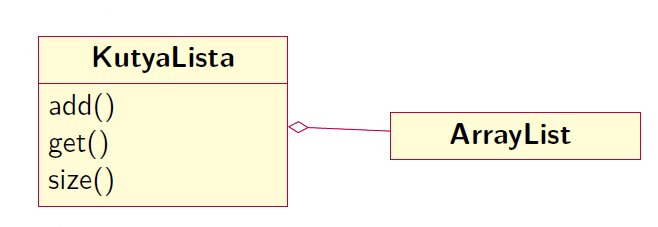
Maga a KutyaLista kompozitként magába foglal egy ArrayListet, amit az add és get metódusokkal kezel, illetve a size metódussal le tudja kérni a lista aktuális méretét. Ez a metódus azért fontos, mert segít abban, hogy a lista elemeit végig tudjuk járni.
Generikus kollekciók¶
Az adott típusra írt tároló osztály a fentiek alapján jól működik, de minden egyes osztályhoz, aminek változóit el szeretnénk tárolni, meg kellene valósítani, ráadásul mindegyik típusú tárolóval. Pont ez motiválta a Java 5 egyik legnagyobb újítását, a generikus típusok, és általuk a generikus tárolók megjelenését. Még annélkül, hogy pontosan elmondanánk mik is azok a generikus típusok, nézzük meg azt, milyen előnyökkel jár a generikus tárolók megjelenése.
A KutyakEsMacskak programunkat írjuk úgy át, hogy most már szimpla ArrayList helyett olyan ArranyListet hozzunk létre benne, ami kizárólag Kutya objektumokat tud tárolni. Ezt a következő programrészlet 21. sorában tesszük meg azzal, hogy egyszerűen az ArrayList után "<" és ">" jelek között megadjuk a Kutya osztályt (hogy ez pontosan mi is, arról kicsit később )
import java.util.*;
class Kutya {
private int kutyaSz;
Kutya(int i) {kutyaSz = i;}
public void print() {
System.out.println(
"Kutya #" + kutyaSz);
}
}
class Macska {
private int macskaSz;
Macska(int i) {macskaSz = i;}
public void print() {
System.out.println(
"Macska #" + macskaSz);
}
}
public class KutyakEsMacskakGen {
public static void main(String[] args) {
ArrayList<Kutya> kutyak = new ArrayList<Kutya>();
for(int i = 0; i < 3; i++)
kutyak.add(new Kutya(i)); // nincs upcast!
//kutyak.add(new Macska(3)); // forditasi hiba
for(int i = 0; i < kutyak.size(); i++)
kutyak.get(i).print(); // nem kell downcast!
//((Kutya)kutyak.get(i)).print();
}
}
Amit ezzel a lehetőséggel kaptunk, az az, hogy innentől kezdve a tárolónk nem Objecteket tárol, hanem a konkrét típust, azaz itt Kutyát. Vagyis a 23. sorban nem lesz upcast Object típusra. Ha véletlen a tárolt típustól eltérő típusú elemet tennénk a tárolóba (ld. 24. sor), az eleve fordítási hiba lenne, tehát ezt már a fordító kivédi. És ami talán még jobb: amikor kiveszünk egy elemet a tárolóból, az eleve a megfelelő típusú, tehát nem kell Objectről átalakítanunk, így megspórolunk egy downcast műveletet is. És bár ez a program így már nem igényli plusz tároló osztály létrehozását, kimenete megegyezik KutyaLista osztály kimenetével.
Iterátorok¶
Ha valaki kicsit jobban elmélyed az egyes tároló osztályok megvalósításában, láthatja, hogy bár valamennyi tároló típus lehetőséget ad arra, hogy lekérjük a bennük levő elemeket, ezek különböző módon lehetségesek, függően az adott tároló típusától. A legtöbbször a tárolás módjától független szeretnénk a tárolók elemeit feldolgozni, bejárni. Mivel azonban az egyes elemeket máshogy érjük el, nincs olyan egységes interface, ami segítene ebben a feladatban.
Minden bejárás így különböző, ami nem praktikus olyan szempontból, hogy lehet, adott esetben egy tároló hosszas használata után döbbenünk rá, hogy céljainkhoz másik tároló használata jobban illett volna. Viszont ha kicseréljük a tárolót, cserélhetünk ki minden olyan kódot a programunkban, ami az adott tároló elemeit járja be. Ahhoz, hogy ez ne így legyen, az iterátorok fogják helyettünk ezt a munkát elvégezni. Az iterátor egy olyan objektum lesz, amely képes végighaladni egy objektumsorozaton annélkül, hogy a programozó tudná, hogy az adott konténernek milyen a belső struktúrája.
A Java iterátor tudása az, hogy minden különböző konténertől lehet kérni az iterator() metódus hívással egy iterátor objektumot, aminek a hasNext() metódusa megmondja, hogy van e még fel nem dolgozott eleme a tárolónak, ha van, akkor a next() metódus visszaad egy, még feldolgozásra álló elemet a tárolóból. A remove() paranccsal pedig az iterator képes az aktuális elemet törölni. Feltételezve, hogy a Kutya és Macska osztályok a korábbaik szerint adottak, a tárolónkat így is bejárhatjuk:
import java.util.*;
public class KutyakEsMacskak {
public static void main(String[] args) {
ArrayList kutyak = new ArrayList();
for (int i = 0; i < 3; i++)
kutyak.add(new Kutya(i));
Iterator i = kutyak.iterator();
while (i.hasNext())
((Kutya)(i.next())).print();
}
}
foreach¶
A Java 5 újítása egy olyan új for szintaxis megjelenése is a nyelvben, ami lehetővé teszi egy-egy tároló elemeinek a bejárását egyesével, ami lényegében ugyanazt csinálja, mint az előző iterátoros példa:
import java.util.*;
public class KutyakEsMacskak {
public static void main(String[] args) {
ArrayList kutyak = new ArrayList();
for (int i = 0; i < 3; i++)
kutyak.add(new Kutya(i));
for (Object o: kutyak)
((Kutya) o).print();
}
}
A Java 5 előtti kollekciók esetében a bejárt elemek típusa értelemszerűen Object, így ezeket a megfelelő típusra kasztolni kell, azonban a generikus tárolók esetében ez is a megfelelő típusú elemeket adja vissza:
import java.util.*;
public class KutyakEsMacskak {
public static void main(String[] args) {
ArrayList<Kutya> kutyak = new ArrayList<Kutya> ();
for (int i = 0; i < 3; i++)
kutyak.add(new Kutya(i));
for (Kutya k: kutyak)
k.print();
}
}
Iterátorok (folyt.)¶
Ismétlésként nézzünk még egy példát:
import java.util.*;
class Horcsog {
private int horcsogSorszam;
public Horcsog(int i) {horcsogSorszam = i;}
public String toString() {
return "Hello, en vagyok a(z) " + horcsogSorszam + ". horcsog";
}
}
class Kiiro {
static void irdKiMindet(Iterator i) {
while (i.hasNext())
System.out.println(i.next());
}
}
public class HorcsogJarat {
public static void main(String[] args) {
ArrayList v = new ArrayList();
for(int i = 0; i < 5; i++)
v.add(new Horcsog(i));
Kiiro.irdKiMindet(v.iterator());
}
}
A példában adott egy Horcsog osztály, minden hörcsögöt egy számmal (jelen esetben egy egyedi sorszámmal) azonosítunk. Ez a horcsogSorszam az egyetlen adattagja így minden hörcsög objektumnak. Magát a toString metódust úgy írjuk meg, hogy ez a sorszám kiírásra kerüljön.
A Kiiro osztály feladata egyetlen, statikus metódus definiálása, amely csupán egy Iterátor objektumot kap, amely iterátorral képes bejárni azt a tárolót, amely az iterátort létrehozta, és a bejárás során kiíratja valamennyi objektumot, amit az iterátor elér (a Horcsog osztályban azért definiáltuk a toString metódust, hogy ez a kiíratás "szép" legyen). Ez nyilván tetszőleges tárolóhoz tartozó Iterator lehet, nem kell megszorítani konkrét tárolóra. Ez a lényeg. Elég általános lesz az az osztály ahhoz, hogyha a HorcsogJarat osztalyban jelen pillanatban ArrayListben tárolt hörcsögeit átrakjuk egy másik kollekció típusba, akkor sem kell ezt a Kiiro osztályt módosítanunk.
Osztályhierarchia¶
Nézzük meg azon osztályok osztálydiagramját, amelyek segíthetnek bennünket az objektumok tárolásában. A diagram jelölésein használjuk az UML diagramoknál megismert jelöléseket, annyi új információval, hogy a szaggatott vonallal kiemelt elemek és kapcsolatok Interface-eket, illetve ezek kapcsolatait jelölik.
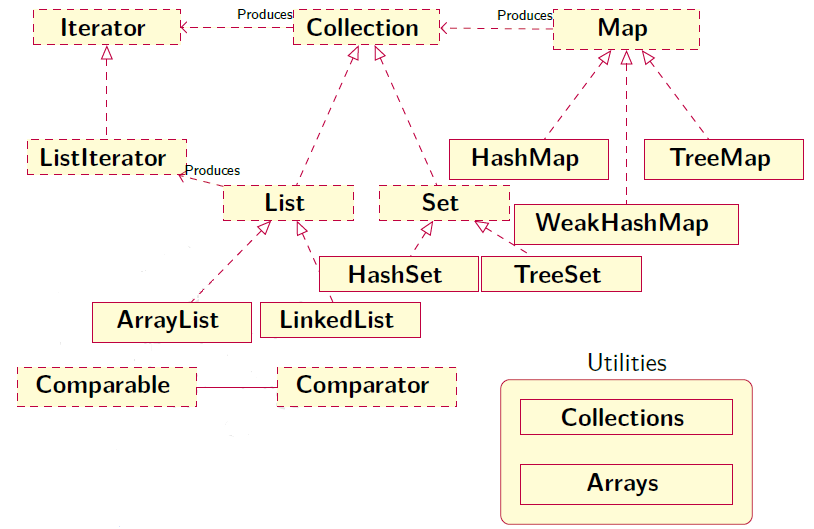
A két nagyobb tároló interface a Collection és a Map, amelyek önmagukban is kapcsolatban állnak egymással, hiszen a Mapek mind a kulcsaikat, mind az értékeiket vissza tudják adni egy-egy kollekcióban. Mind a Collectionnek, mint a Mapnak speciális megvalósításaik lehetnek, ezeket később alaposabban is megnézzük. Minden esetben ezek használatakor el kell döntenünk, mely tulajdonságokkal rendelkeznek az adataink, és milyen tulajdonságokat várunk el a maguktól a tárolóktól (pl. sokszor akarunk beszúrni elemeket, gyorsan akarjuk elérni az elemeket, stb...)
A kollekciók bejárását az Iterator interface biztosítja, amelyet minden speciális kollekciónak meg kell saját maga valósítania.
A tömböknél láttuk, hogy a Comparator és Comparable interface-ek segíthetnek a tömbelemek rendezésében, de sok esetben használatosak a többi tárolónál is.
Végezetül láttuk, hogy olyan osztálykönyvtárak is akadnak, amik leveszik a programozók válláról azon gyakori feladatokat, amik egy-egy sokszor előforduló, az objektumok tárolásával, rendezésével kapcsolatosak. Ilyenek például a Collections és Arrays osztályok.
Lista¶
A lista egy olyan interface leírást ad, amely feltételezi, hogy a benne tárolt adatokat egymás után, egy megadott sorrendben tároljuk. Bejárásukat a ListIterator teszi lehetővé, amely a lista első elemétől adja vissza az elemeket a lista utolsó eleméig, illetve ezzel lehetőség van arra is, hogy a listába elemeket szúrjunk be.
Konkrét lista megvalósítás több is létezik. Az egyik a példákból már jól ismert ArrayList, amely tulajdonképpen egy tömbbel megvalósított lista, így a tömbök minden előnyével és hátrányával rendelkezik. Azaz az elemeket gyorsan el tudjuk érni, de a beszúrás és törlés műveletek lassúak lehetnek, hiszen ilyenkor várhatóan sok-sok tömb elemet át kell mozgassunk. Másik megoldás a LinkedList, azaz láncolt lista, amibe a beszúrás ugyan gyors, de egy elem elérése lassú, az ArrayListhez képest, hiszen mindig a lista elejéről (esetleg végéről) indulva be kell járni a listát az adott elem eléréséig. Ha valaki szeretné a láncolt listát stackként, queue-ként, vagy deque-ként használni, ezt könnyűszerrel meg is teheti, hisz ez az osztály implementálja azon metódusokat, amik ezekhez az absztrakt adattípusokhoz elengedhetetlenek, mint pl. addFirst(), addLast(), getFirst(), getLast(), removeFirst(), removeLast().
Halmaz¶
A halmaz, avagy a Set interface az elemeket sorrendiség nélkül tárolja. Az Object osztályban definiált equals metódus segítségével hasonlítják össze a halmaz absztrakt adattípus metódusai az egyes eltárolt elemeket, ezzel meghatározva egy konkrét elem helyét a halmazban.
Konkrét megvalósítások a HashSet, amelyben az objektumok egy hash érték alapján tárolódnak el, az elemek gyors keresését biztosítja. A hatékonyságot növelhetjük a legmegfelelőbb hash megadásával, amit a hashCode metódus felüldefiniálásával adhatunk meg.
A TreeSet megvalósításban az elemek eleve egyféle rendezés alapján tárolódnak, nevét a tárolás módjáról kapta, hiszen az elemek egy fa adatszerkezetbe kerülnek. Mivel az elemek rendezettek, így a first() és last() metódusok könnyen vissza tudják adni a legkisebb és legnagyobb elemeket. Egyéb metódusokkal, mint amilyen a subSet(from,to), headSet(to), tailSet(from) egy-egy részhalmazát kaphatjuk vissza a rendezett elemeknek.
Collection (List, Set) funkcionalitása¶
A lista és halmaz absztrakt adattípusok számos metódust definiálnak. Ezek közül a legfontosabbak:
| Metódus | Leírás |
|---|---|
| boolean add(Object) | elem hozzáadása |
| boolean addAll(Collection) | elemek hozzáadása |
| void clear() | töröl minden elemet |
| boolean contains(Object) | true, ha tartalmazza az elemet |
| boolean containsAll(Collection) | true, ha tartalmazza az elemeket |
| boolean isEmpty() | true, ha üres |
| Iterator iterator() | készít egy iterátort |
| boolean remove(Object) | elem törlése |
| boolean removeAll(Collection) | elemek törlése |
| boolean retainAll(Collection) | csak akkor tartja meg az elemet, ha az szerepel a paraméterben (metszetképzés) |
| int size() | elemek száma |
| Object[] toArray() | felépít egy tömböt, amely tartalmazza a kollekció elemeit |
| T[] toArray(T[]) | mint az előző, csak a paraméterben kapott tömb futásidejű típusának megfelelő típusú tömböt épít fel |
Leképezés¶
A leképezés, vagyis a Map absztrakt adattípus kulcs-adat párokat tartalmaz. Általában a kulcsra valósul meg egy gyors keresés. Jellegzetessége ennek az adatszerkezetnek Javaban, hogy mind a kulcsok, mind az értékek kollekcióját is képes visszaadni.
Konkrét megvalósítások a HashMap, ami a kulcsok hash értéke alapján a keresés, illetve beszúrás műveletek gyorsaságára optimalizál. A TreeMap pedig egy olyan adatszerkezet, ami a kulcsokat egy piros-fekete fa segítségével rendezetten tárolja, így értelmes művelete a firstKey() és lastKey() metódusok, amik visszaadják a legkisebb és a legnagyobb kulcsokat. Ezen kívül a subMap(from,to), headMap(from), tailMap(to) visszaadják a fának egy részét.
Map funcionalitása¶
Mapek esetében is adottak azok a metódusok, amelyet maga az interface definiál. Ezek a következők:
| Metódus | Leírás |
|---|---|
| void clear() | töröl minden elemet |
| boolean containsKey(Object) | true, ha tartalmazza kulcsként a kapott elemet |
| boolean containsValue(Object) | true, ha tartalmazza értékként a kapott elemet |
| Set entrySet() | visszaadja halmazként a tárolt adatokat |
| Object get(Object key) | a kapott kulcsú elemet adja vissza |
| boolean isEmpty() | true, ha üres |
| Set keySet() | visszaadja halmazként a tárolt kulcsokat |
| Object put(Object key, Object value) | beszúr egy új elemet (párost) |
| void putAll(Map) | beszúrja a kapott Map elemeit |
| Object remove(Object key) | törli a kapott kulcsú elemet |
| int size() | elemek száma |
| Collection values() | visszaadja kollekcióként a tárolt elemeket |