Elemi adatípusok
Elemi adattípusok¶
Az elemi adattípusok közé tartoznak azok az adattípusok, amelyek értékhalmaza elemi értékekből áll, azaz nem összetett adatok alkotják. Ezeket az elemi adattípussal rendelkező értékeket már nem lehet további, önmagukban is értelmes részekre bontani.
A C nyelv a következő elemi adattípusokkal rendelkezik:
- egész típus (azaz
inttípus, amely típus értelmezési tartományának nagyságát módosíthatjuk asigned,unsigned,short,longmódosítókkal) - karakter típus (azaz
chartípus, amely értelmezési tartománya asigned,unsignedmódosítókkal lehet variálni) - felsorolás típus (az előbbi típusok felhasználásával az
enumtípusképzéssel) - logikai típus (C-ben nincs közvetlen megvalósítása, a \(C^{99}\) szabvány építi be a nyelvbe)
- valós típusok (
float,double, éslong doubletípusok)
Ha a nyelv szintaktikája szerint a program egy adott pontján egy típusnak kellene következnie, de az hiányzik, a fordító a típus helyére automatikusan int-et helyettesít.
Ezzel a legelső programunknál már találkoztunk is, ahol a main függvény elé nem tettük ki az int-et, de ennek ellenére szabályos programot tudtunk írni.
Egy 32 bites architektúrán a C nyelv elemi adattípusainak a méretét, illetve értelmezési tartományát az alábbi táblázat foglalja össze:
| C típus | méret (bájt/bit) | alsó határ | felső határ |
|---|---|---|---|
char |
1 / 8 | fordító függő | fordító függő |
signed char |
1 / 8 | -128 (-27) | 127 (27-1) |
unsigned char |
1 / 8 | 0 | 255 (28-1) |
short int |
2 / 16 | -32 768 (-215) | 32 767 (215-1) |
signed short int |
2 / 16 | -32 768 (-215) | 32 767 (215-1) |
unsigned short int |
2 / 16 | 0 | 65 535 (216-1) |
int |
4 / 32 | -2 147 483 648 (-231) | 2 147 483 647 (231-1) |
signed int |
4 / 32 | -2 147 483 648 (-231) | 2 147 483 647 (231-1) |
unsigned int |
4 / 32 | 0 | 4 294 967 295 (232-1) |
long int |
4 / 32 | -2 147 483 648 (-231) | 2 147 483 647 (231-1) |
signed long int |
4 / 32 | -2 147 483 648 (-231) | 2 147 483 647 (231-1) |
unsigned long int |
4 / 32 | 0 | 4 294 967 295 (232-1) |
long long int |
8 / 64 | -263 | 263-1 |
signed long long int |
8 / 64 | -263 | 263-1 |
unsigned long long int |
8 / 64 | 0 | 264-1 |
float |
4 / 32 | -3.4028234663852886E+38 | 3.4028234663852886E+38 |
double |
8 / 64 | -1.7976931348623157E+308 | 1.7976931348623157E+308 |
long double |
8 / 64 | -1.7976931348623157E+308 | 1.7976931348623157E+308 |
Amit megfigyelhetünk a táblázat alapján, azok a következők:
- az előjeltelen számok (
unsigned) értelmezési tartománya 0-tól kezdődik, csak nemnegatív számokat tudunk velük reprezentálni, - az előjeles (
signed) értékek esetén eggyel több negatív érték ábrázolható, mint pozitív, és - valós értékeket minden esetben előjelesen kezelünk.
Egész típusok a C nyelvben¶
A C nyelvben az egész típus tárolására az int adattípust használjuk.
Illetve használhatjuk még a char típust is, ha kisebb számokat szeretnénk csak megjeleníteni.
A táblázatból már láthattuk, hogy az értelmezési tartomány az alábbi kulcsszavakkal módosítható:
signed: a típus előjeles értéket fog tartalmazni. Egy bit az előjelhez lesz felhasználva, nem az érték nagyságához.unsigned: a típus előjeltelen, nemnegatív értéket fog tartalmazni, minden bit felhasználható az érték nagyságához.short: kevesebb biten tárolódik, így kisebb az értelmezési tartománya. Ez a módosító már nem tehető ki acharelé.long: ábrázolására több bit áll a rendelkezésre, azaz több érték ábrázolható vele. Akár duplán is alkalmazható (long long), és acharelé szintén nem kerülhet oda.
Az egész típusok az értelmezési tartomány határain belül valamennyi egész számot pontosan ábrázolnak.
Az egyes gépeken, architektúrákon az egyes típusok mérete más-más lehet, de minden C megvalósításban igaz az, hogy a short típus mérete, azaz az ábrázoláshoz felhasznált bitek száma, legfeljebb akkora, mint az int típus mérete, ami legfeljebb akkora, mint a long mérete, ami pedig legfeljebb akkora, mint a long long mérete.
A C nyelv különböző egész típusai bár különböznek az értelmezési tartományukban, ugyanolyan műveleteket tudunk rajtuk végrehajtani. Egész kifejezésben bármely egész típusú tényező szerepelhet. Amire az egyes műveletek végrehajtásánál figyelni kell, hogy a műveletvégzés értékkészlete nem lóghat túl az eredmény adattípusának értelmezési tartományán, hiszen ez esetben az eredményt adott adattípussal nem tudjuk ábrázolni, illetve a kapott eredmény félrevezető lesz.
Egész literál típusa az a legalább int méretű egész típus, amely a legszűkebb olyan értelmezési tartománnyal rendelkezik, amelynek eleme a kifejezés értéke, ha a számleírás suffixsze (utótagja) ezt nem módosítja.
Az l suffix a long módosítót, az u az unsigned módosítót képviseli.
Egy egész kifejezés típusát csak és kizárólag a benne található részkifejezések határozzák meg oly módon, hogy egy művelet kiértékelésekor az eredmény típusa a két operandus típusa közül a "nagyobb" lesz. Értékadáskor a jobb oldalon álló kifejezés kiértékelése független attól, hogy a bal oldalon milyen típusú változó van.
Az egész típus esetében a műveletek lehetnek aritmetikai műveletek, ahol az +, -, és * a matematikában megismert alapműveleteket, a / és % pedig a maradékos osztás egészrészét illetve maradékát jelenti.
Ezen kívül lehetnek relációs műveletek, amelyek egész típusok értékeit hasonlítják össze: <, <=, >, >=, ==, !=, illetve beszélhetünk bitenkénti logikai műveletekről, amelyeket a későbbiekben részletesen tárgyalunk.
Azonban előtte nézzük meg, hogyan is ábrázoljuk az egész érétékeket a számítógépen! Tegyük fel, hogy adott n bitünk egy egész tárolására! Az n bit összesen \(2^n\) állapotot (azaz \(2^n\) számot) tud megkülönböztetni.
Egész típusoknál az értékhalmaz szokásos leképezése a következő:
- Ha negatív számok nem szerepelnek az értékhalmazban (
unsignedtípusok), akkor az értékhalmaz a \([0 \dots 2^n-1]\) zárt intervallum. Az n egymás utáni biteket bináris számként értelmezve kapjuk meg a reprezentált értéket, illetve az értéket bináris számként felírva és n számjegyig balról 0 számjegyekkel kiegészítve kapjuk a számot leíró bitsorozatot. - Ha az értékhalmazban negatív számok is szerepnek, akkor az értékhalmaz a \([-2^{n-1} \dots 2^{n-1}-1]\) zárt intervallum. A nemnegatív értékek tárolása és a 0 értékű bittel kezdődő n bites bitsorozat ugyanaz, mint a fenti eset, vagyis a szám kettes számrendszerbeli alakja (bevezető 0 bitekkel kiegészítve). Figyeljük meg, hogy ezekben az esetekben a legelső bit mindig 0. A negatív \(x\) értékek tárolása úgy történik, mintha az \(x + 2^n\) kifejezést próbálnánk nemnegatív számként n biten tárolni. Ezek az esetek így mindig 1-es bittel kezdődnek. Az 1-essel kezdődő bitsorozat pozitív számként értelmezett értékéből levonva a \(2^n\) értéket kapjuk a reprezentált negatív értéket.
A példa kedvéért legyen n=4, azaz próbáljuk a legfeljebb 4 biten ábrázolható számokat ábrázolni. Mivel \(2^n = 16\), így összesen 16 értéket, számot tudunk megkülönböztetni. Amennyiben előjeltelen számaink vannak csak, akkor ezt a 16 értéket a \([0 \dots 15]\) itervallum elemei határozzák meg. Előjeles esetben a \([-8 \dots 7]\) értékeket tudjuk ábrázolni. Az alábbi ábrán jól látszódik, hogy az előjeltelen \([8 \dots 15]\) értékek fizikailag pontosan ugyanúgy tárolódnak, mint az előjeles \([-8 \dots -1]\) értékek.
Például vegyük a -6 értéket! Ahhoz, hogy ezt eltároljuk, adjunk hozzá \(2^4 = 16\)-ot, és tároljuk le a kapott értéket, ami nem más, mint a 10. Ha csak a bitsorozat áll rendelkezésünkre, akkor amennyiben a bitsorozat 1-essel kezdődik, és a számunk előjeltelen, akkor a bitsorozat által reprezentált szám a megjelenítendő szám (például: 1010 bitsorozat a 10-et jelöli ). Amennyiben előjeles számokkal dolgozunk, akkor ugyanez a bitsorozat a \(10-16=-6\) értéket reprezentálja.
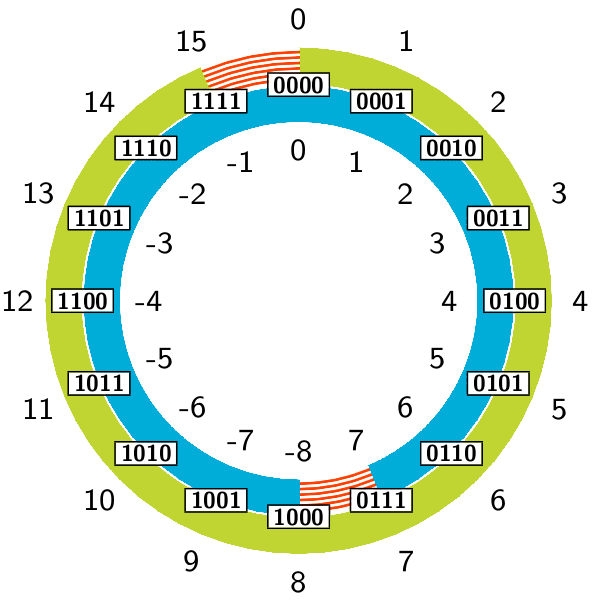
A negatív számoknak ezt a tárolását szokás kettes komplemensnek hívni. Egy x érték kettes komplemense úgy is megadható, hogy x-et negáljuk (\(~x\)), azaz minden bitjénél a 0 bitek helyére 1, az 1-esek helyére 0 kerül, majd az így kapott számhoz hozzáadunk 1-et. A -6-os példánk esetében \(x=0110\), azaz \(~x=1001\), amiből jön, hogy a kettes komplemens értéke: \(1001 + 1 = 1010\).
Típusok határértékei¶
Mivel a C szabvány nem definiálja pontosan az egyes típusok méreteit, az, hogy egy-egy típus mekkora, függ a rendszertől és az architektúrájától.
Ezért nem érdemes fixen építeni a típusok korlátainak ismeretére.
Ehelyett használjuk azokat a konstans értékeket, amelyeket a limits.h-ban megtalálhatunk.
Ehhez a forrásunk elején húzzuk be ezt az állományt a #include <limits.h> sorral.
Egy 32 bites rendszeren ilyen definíciókat találunk ebben:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
Tip
Figyeljük meg a konstans literálokat, illetve a bennük használt suffixeket!
Karakter adattípus a C nyelvben¶
Ahogy az az előző fejezetekből kiderült, a karakter adattípus egy olyan adattípusa a C-nek, amely egész kicsi (1 bájton ábrázolható) egész számok tárolására alkalmas.
Ennek ellenére a char típus karakterek (azaz betűk és számok) tárolására való.
A típust jellemzi ez a kettősség: ha akarom számként, ha akarom karakterként értelmezhetem a tárolt értéket.
Az, hogy melyik számértékhez melyik karakter tartozik, az alkalmazott kódtáblától függ (ami összerendeli a számokat a karakterekkel).
Éppen ezért nem tanácsolt a forráskódban konkrét karakterkóddal hivatkozni egy-egy karakterre.
Bár magában a programban egy karakter megadható a kódjával, azaz egy számértékkel is, tanácsosabb a konkrét karaktert használni aposztrófok (') között.
A kódtábláról csak annyit feltételezhetünk, hogy az ábécének megfelelően igaz a kisbetűk és a nagybetűk kódjaira, hogy az ábécében hamarabb szereplő betű kódja kisebb a később szereplő betűknél, azaz 'a'<'b'<...<'z', valamint 'A'<'B'<...<'Z'.
Azt, hogy a kisbetűk kódolása megelőzi a nagybetűkét, nem lehet kijelenteni (sőt, az ASCII táblában konkrétan a nagybetűk vannak előrébb).
A számjegyek esetében annyit még feltételezhetünk, hogy a soron következő számjegyek kódjainak a különbsége mindig 1.
Azaz '0' + 1 == '1', . . . , '8' + 1 == '9'
A C nyelv alapvetően az ASCII kódtáblát használja (ez a 0 és 127 közötti kódú karaktereket rögzíti), de a megjelenített karaktertérkép nagyon sokmindentől függ. A nem ASCII karakterekkel vigyázzunk, mert pl. az UTF8 kódolás esetén egyes karakterek (pl. az ékezetes betűk) több bájton tárolódnak, és ezt a C nyelv nem tudja kezelni.
Bizonyos karakterek (általában a rendezés szerint első néhány) vezérlő karakternek számítanak, és nem megjeleníthetők, azaz ha megpróbáljuk őket kiírni egy kiírató utasítással, nem konkrét karaktert fogunk látni, hanem valami mást tapasztalunk (például, hogy a következő karakter a következő sorban jelenik meg). A speciális karaktereket, illetve magát az aposztrófot is (és persze végső soron minden karaktert) megadhatunk úgynevezett escape-szekvenciákkal is. Ezeket a \ (backslash) karakterrel kell kezdeni.
Nézzünk erre néhány példát!
| Megnevezés | Escape szekvencia |
|---|---|
| újsor | \n |
| vízszintes tab | \t |
| backslash | \\ |
| aposztróf | \' |
| 0ddd kódú karakter | \ddd |
| kocsi-vissza | \r |
| backspace | \b |
| lapdobás | \f |
| csengő | \a |
| null karakter | \0 |
Mint említettük, a char típus egészként is használható.
A konverzió a kétfajta megadott érték között automatikus, így például a '\ddd' == 0ddd, vagyis ASCII kódtábla esetén például '\060' == '0' == 48 == 060, '\101' == 'A' == 65 == 0101, '\172' == 'z' == 122 == 0172.
Feladat
Konvertáljunk egy tetszőleges számjegy karaktert (ch) a neki megfelelő egész számmá és egy egyjegyű egészet (i) karakterré!
Megoldás
1 2 | |
Feladat
Konvertáljunk kisbetűt (ch) nagybetűssé (CH) és fordítva!
Megoldás
1 2 | |
Bitenkénti logikai műveletek¶
Mint említettük, a C nyelv a magas szintű struktúrái mellett (pl. vezérlési szerkezetek) az alacsony szintű programozást is nyelvi szinten elérhetővé teszi.
Ezért a C nyelv egész típusú (azaz int és char) értékeire definiálva vannak a bitmanipulációs operátorok.
Ezek a műveletek az egész számokat az ábrázolási módjuknak megfelelő bináris számként, azaz 0 és 1 számjegyek, bitek sorozataként kezelik.
Logikailag a 0 érték a hamis értéket, az 1 érték az igazat jelenti.
Egyetlent olyan bitenkénti művelet van, amely egy operandussal rendelkezik, a negáció (~).
Ez a művelet egy adott bitsorozat valamennyi bitjét az ellenkezőjére állítja.
Általában maszkok kialakítására szokás használni.
Például a MASK = ~3 a maszk utolsó két bitjét 0-ra állítja.
Az, hogy a 0 értékek előtt hány darab egyes bit van, az a MASK aktuális típusától függ, de ezzel így a programozónak nem kell foglalkoznia.
Két operandusú bitenkénti művelek a következők:
&: bitenkénti 'és' művelet - a két operandust egymás mellé állítja, az egymásnak megfelelő bitekre "és" műveletet végez. Amennyiben mind a kettő igaz (azaz 1-es), akkor az eredmény bit is 1-es, egyébként az eredmény bit 0 értéket kap. Ezt a műveletet általában maszkolásra szokás használni, azaz egyes bitek 0-ra állítására. Például a(v & 1)kifejezés eredménye, hogy avérték minden egyes bitjét 0-ra állítja, kivéve az utolsót, amely 1 lesz, havutolsó bitje 1 volt (azazvpáratlan), és 0 lesz egyébként, azaz havpáros.|: bitenkénti 'vagy' művelet - a két operandust egymás mellé állítja, az egymásnak megfelelő bitekre "vagy" műveletet végez. Amennyiben legalább az egyik igaz (azaz 1-es), akkor az eredmény bit is 1-es, egyébként az eredmény bit 0 értéket kap. Ezt a műveletet az egyes bitek 1-re állítására szokás használni. Például av |= MASKértékadásban avváltozó azon bitjeit, amelyek aMASK-ban 1-esek voltak, szintén 1-re állítja, a többit nem változtatja meg.^: bitenkénti 'kizáró vagy' művelet - a két operandust egymás mellé állítja, az egymásnak megfelelő bitekre 'kizáró vagy' műveletet végez. Ekkor az eredmény bit akkor, és csak akkor lesz igaz, ha az egymásnak megfeleltetett bitek közül az egyik, és csak egyik igaz. Általában bitek összehasonlítására, átbillentésére szolgál. Például av ^= MASKértékadásbanvazon bitjeit, melyek aMASK-ban 1-esek voltak megváltoztatja, a többit nem.<<balra léptetés - az első operandus bitsorozatának összes bitjét balra mozgatja a második operandus értékének megfelelően. A bejövő bitek helyére0érték kerül. Gyakran használják ezt a műveletet kettő hatvánnyal való szorzásra, vagy bit kiválasztásra. Például aMASK = 1 << 8egy olyan maszkot hoz létre, ahol a \(2^8\) helyiértékű bit lesz 1-es, ami tulajdonképpen az \(1*2^8\) érték.>>: jobbra léptetés - az első operandus bitsorozatának összes bitjét jobbra mozgatja a második operandus értékének megfelelően. A bejövő bitek helyére előjeles kifejezés esetében az előjel bit kerül, előjeltelen típus esetén a 0. Gyakran használják ezt a műveletet a kettő hatvánnyal való osztásra:v >>= 8avértékét \(2^8\)-nal osztja.
Példák bitenkénti műveletekre¶
Feladat
Határozzuk meg a ~0x16 kifejezés értékét (egybájtos típus esetén)!
Megoldás
A 0x szintaktikai jelentése a számformátum elején, hogy az adott szám 16-os számrendszerben adott.
Azaz minden számjegye egy 16-os számrendszerbeli szám, vagyis minden számjegye egy 4 hosszúságú bitsorozattá alakítható.
Alakítsuk át tehát a számot a megfelelő bitsorozattá számjegyenként!
Kapjuk, hogy a ~00010110 műveletet kell elvégezni.
Azaz ebben a bitsorozatban kell minden bitet az ellenkezőjére állítani.
Így kapjuk, hogy az eredmény az 11101001.
4-esével a biteket egy-egy hexadecimális számjeggyé alakíthatjuk a bináris formát.
Vagyis ~0x16=0xe9.
Feladat
Határozzuk meg a 0x16 & 0x3a kifejezés értékét (egybájtos típusok esetén)!
Megoldás
Hasonlóan az előbbi megoldáshoz, a műveletben szereplő értékekre határozzuk meg azok bináris reprezentációját! Mivel a műveletet bitenként kell elvégezni, így a két operandust tegyük egymás alá, így szépen látszódnak a bit párok:
1 2 3 | |
0x16 & 0x3a = 0x12.
Feladat
Határozzuk meg a 0x16 | 0x3a kifejezés értékét (egybájtos típusok esetén)!
Megoldás
Hasonlóan az előbbi megoldáshoz, a műveletben szereplő értékekre határozzuk meg azok bináris reprezentációját! Mivel a műveletet bitenként kell elvégezni, így a két operandust tegyük egymás alá, így szépen látszódnak a bit párok:
1 2 3 | |
0x16 | 0x3a = 0x3e.
Feladat
Határozzuk meg a 0x16 ^ 0x3a kifejezés értékét (egybájtos típusok esetén)!
Megoldás
A két bináris reprezentációt egymás alá helyezve végezzük el a műveletet:
1 2 3 | |
0x16 ^ 0x3a = 0x2c.
Feladat
Határozzuk meg a 0x16 << 4 és 0x96 << 4 kifejezések értékét (egybájtos típusok esetén)!
Megoldás
Vegyük mindkét szám bináris reprezentációját, majd 4 bitet léptessünk rajtuk balra! Mindkét szám továbbra is 8 bites lesz, a kieső bitek elvesznek. Az újonnan bekerülő bitek pedig 0-ák lesznek.
1 2 | |
0x60.
1 2 | |
0x60.
Feladat
Határozzuk meg a 0x16 >> 4 és 0x96 >> 4 kifejezések értékét úgy is, ha az adott kifejezés előjeles, úgy is, ha előjeltelen (egybájtos típusok esetén)!
Megoldás
Vegyük mindkét szám bináris alakját! Léptessük őket jobbra 4 bitet! Jobb oldalról előjeltelen esetben 0-ák kerülnek be, előjeles esetben pedig a legelső (előjel) bitnek megfelelő érték.
Előjeltelen (unsigned eset):
1 2 | |
0x03.
1 2 | |
0x09.
Előjeles (signed eset):
1 2 | |
0x03, mint az előbb (unsigned esetben).
1 2 | |
0xf9, ami nem egyezik meg az előzővel.
Nagyon fontos, hogy a bitenkénti és a normál logikai műveletek különböznek egymástól.
Azaz a & és | bitenkénti műveletek nem ugyanúgy viselkednek, mint a && és || logikai műveletek.
A bitműveletek az érték egészét nézve tulajdonképpen matematikai műveleteknek tekinthetők, amelyek mindkét operandust felhasználják.
Logikai műveletek esetén az operandusok csak szükség szerint balról jobbra értékelődnek ki.
Ha már az egyik részkifejezés értéke meghatározza a teljes kifejezés értékét, akkor a másik rész nem fog kiértékelődni.
Ezt nevezzük lusta kiértékelésnek vagy rövidített kiértékelésnek.
Ráadásul az eredmény logikai értéke is különbözhet.
Ha például x értéke 1, y értéke 2, akkor x & y értéke hamis, hiszen a két számban különböző helyen vannak az 1-es bitek, vagyis az eredmény minden bitje 0 lesz, ami összességében a 0 értéket reprezentálja, amit hamisként értelmezünk.
Az x && y kifejezés értéke viszont igaz lesz, hiszen mind az 1, mind a 2 logikailag igaz értéknek tekinthetőek, így éselésük is igaz értéket ad.
Feladat
Láttuk, hogy az, hogy a char típus vagy signed, vagy unsigned.
Az hogy konkrétan milyen, a fordítótól függ.
Feladat egy olyan program írása, amely eldönti, hogy a char típus előjeles, vagy előjeltelen értékeket tárol!
Megoldás
A fentiek alapján a megoldás alapja az, hogy megnézzük, hogy egy konkrét értéket jobbra léptetve bekerül-e az előjel bit, vagy sem.
Az egy unsigned char ugyanúgy viselkedik-e egy adott jobbra léptetős művelet esetében, mint a sima char.
Ha igen, akkor nincs különbség char és unsigned char között:
1 2 3 4 5 6 7 8 9 | |
Típusképzés¶
A C nyelvben lehetőség van arra, hogy a típusokat tetszés szerint elnevezzük, avagy saját típusokat definiálhatunk, amit a typedef kulcsszóval tehetünk meg.
Új típus megadása a következő alakban lehetséges:
typedef típus új_típusnév;
Amint így egy típust definiáltunk, az új típusnévvel, mint azonosítóval is hivatkozhatunk egy adott típusra.
Ennek egyik értelme lehet az, hogy bonyolultabb típuskifejezéseket egyszerűbb típussal helyettesítjük.
Például az igen hosszú unsigned long long int típust a typedef unsigned long long int ulli; utasítással ulli-nek keresztelhetjük, amelyet gyorsan és könnyeden tudunk használni.
Az is lehet azonban, hogy bizonyos helyen nem vagyunk még tisztában azzal, hogy a program adott futásai milyen értékhalmazokkal fognak dolgozni adott változó esetén.
Ilyenkor, ha a lehető legnagyobb típust használjuk, és a végül kiderül, hogy ez túlzó volt (mondjuk mindenhol unsigned int-et használunk char helyett), akkor a program feleslegesen használ memóriát.
Jó lenne persze ilyenkor az összes helyen lecserélni az adott típust, de ez nem feltétlen egyszerű feladat.
Ha azonban már eleve úgy dolgozunk, hogy az adott típus helyén egy alias van, akkor elég a típusdefiníciót megváltoztatni, és máris módosíthatjuk a memória igényét a programnak.
Felsorolás adattípusok C nyelvben¶
A felsorolás adattípus egy olyan speciális egész értékeket megadó típusa a C nyelvben, amelyben a típus elemeit egy felsorolás határozza meg. Ebben a felsorolásban az egyes elemeket egy-egy azonosítóval adunk meg egymás után, ahol minden egyes azonosítónak meglesz a maga konkrét értéke. Felsorolás adattípus esetén elképzelhető, hogy egy-egy azonosító ugyanazt az értéket jelenti. Bár össze is adhatjuk ezen felsorolási típus értékeit, azonban nagyon könnyen ez a művelet kivezet a típus értelmezési tartományából. Inkább csak az értékadás művelet az, amit biztonsággal lehet használni ennél a típusnál, illetve a relációs műveletek. Az elemek reláció szerinti sorrendjét a típusképzés során az elemek felsorolási sorrendje definiálja, hacsak nem adunk az elemeknek konkrét értéket.
Felsorolási adattípust az enum kulcsszóval definiálhatunk: enum {elem_1, ..., elem_n};.
Például:
1 2 3 4 5 6 | |
typedef segítségével létrehoztunk egy het_t típust, amely típus ezután normál típusként használható, és segítségével változókat deklarálhatunk, ahogy azt tettük a het_t nap;utasításban.
Ha nem hozunk létre egy új típust, akkor a nap változó deklarációjának kell tartalmaznia a típus megadását, illetve az elemek felsorolását.
Ez is járható út persze, akkor és csak akkor, ha a típust máshol nem akarjuk felhasználni.
A felsorolás típus C nyelven nagyon szorosan kötődik az int típushoz.
Alapesetben a felsorolásban szereplő első elem értéke 0, a többié 1-gyel több, mint az őt megelőző elem.
Ezért is mondtuk, hogy alapesetben az azonosítók felsorolása megadja a < rendezési relációt.
Azonban a C lehetővé teszi, hogy módosítsuk a felsorolt elemek értékét, és egy-egy azonosítóhoz közvetlen értékeket rendelhetünk. Így például az
1 | |
hetfo azonosító értéke 1 lesz (0 helyett).
Mivel a többi esetben nem definiáltuk az elemek értékét, így azokra igaz lesz az, hogy 1-gyel nagyobbak, mint az előttük levő elem értéke.
A típusképzésben felsorolt azonosítók úgy működnek, mintha abban a blokkban deklarált konstans azonosítók lennének, amelyik blokkban a típusdefiníció szerepel. Így a C nyelvben az is lehetséges, hogy egy típuson belül több azonosító ugyanazt az értéket kapja. Azaz az
1 | |
a és e (illetve a b és f) azonosítók ugyanazt az értéket kapják.
Látszik, hogy a kapcsolat a egész és a felsorolási típus között igen erős.
Ennek oka, hogy a fordító az enum-ot teljes mértékben az int típusra vezeti vissza, ezért ennek a típusnak a műveletei megfelelő körültekintéssel használhatóak az enum típuson is.
Nézzük az alábbi egyszerű példát!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
Definálva a hét napjait a fenti módon megkaphatjuk mindig a soron következő napot, ha az adott nap értékéhez hozzáadunk 1-gyet.
Azonban a vasarnap esetében akármennyire is szeretnénk, az a + 1 hatására nem a hétfőt kapjuk.
Itt az összeadás művelete kivezet a felsorolás típus értelmezési tartományából.
Ami persze a fenti kód esetében jó is, ha a célunk a napok egyszeri bejárása a for ciklusban.
Viszont ha periódikusan ismételni szeretnénk egy tevékenység sorozatot a hét napjain, akkor már jobb, ha a napok inkrementálását körültekintően, a KovNap metódusban meghatározott módon tesszük meg.
Logikai adattípus C nyelven¶
Az alap C nyelvnek nem volt része a logikai adattípus, ezt csak a \(C^{99}\) szabvány vezette be, amely a _Bool típussal egy olyan {0, 1} értékkészlettel rendelkező típust definiál, amely segítségével a logikai értékeket reprezentálni tudja a nyelv.
Azonban ez nem azt jelenti, hogy ezelőtt nem létezett logikai érték a C nyelvben.
Egész egyszerűen a műveletek eredményeként keletkező logikai hamis értéket a 0 egész reprezentálja, és minden 0-től különböző érték logikai értelemben igaznak számít.
Ezen konverziók szerint a logikai és egész értékek teljesen konvertibilisek a C nyelvben, azaz logikai értéket tudunk egész típusú változókban is tárolni (illetve csak abban tudtunk a \(C^{99}\) szabvány bevezetése előtt).
A \(C^{99}\) szabvány bevezette az stdbool.h headert is, ez definiálja az elegánsabb bool típust, valamint a false és true literálokat, amiket a hamis, illetve igaz logikai értékek reprezentálására használhatunk.
Ha nem akarjuk azonban ezt használni, akkor magunk is definiálhatunk logikai típusokat.
Erre több lehetőségünk is van:
1 2 | |
vagy
1 2 3 4 5 6 | |
Esetleg bevezethetünk saját típust is:
1 | |
Arra ügyelni kell, hogy továbbra sem csak a true vagy TRUE érték lesz logikai igaz értékként értelmezve!
Valós típusok a C nyelvben¶
A C nyelvben két típus is adott arra, hogy a valós számokat reprezentáljuk.
Ezek a float és a double típusok.
Látni fogjuk, hogy a valós számok ábrázolása technikailag mindig egy kicsit pontatlan lesz a számítógépeken, hiszen nem tudunk csak diszkrét értékeket tárolni, így minden valóst csak egy maghatározott pontossággal tudunk megadni.
Amit garantálni lehet, hogy egy adott valós típussal az értékkészletének határain belül minden értéket képesek vagyunk egy e relatív pontossággal ábrázolni, azaz minden a valós számhoz megadható az az a-hoz legközelebbi az adott valós típuson ábrázolható x érték, amelyre \((|(x-a)/a| \leq e)\) teljesül.
A float és a double adattípusok értelmezési tartományukon túl abban különböznek egymástól, hogy mi az a pontosság, amivel a valós értékeket közelíteni tudják.
A double típus esetén a long módosítóval lehetőségünk van az értelmezési tartomány bővítésére (de ez architektúrafüggő).
Amit el tudunk mondani az egyes típusok méretére vonatkozóan mondani az az, hogy a float típus mérete legfeljebb akkora, mint a double mérete, ami legfeljebb akkora, mint a long double mérete.
Bár értékkészletükben eltérnek ezek a típusok, értelmezett műveleteikben megegyeznek. Valós kifejezésen belül bármely valós vagy egész típusú tényező előfordulhat, akár vegyesen is. Ami fontos, és amire már láttunk példát az egész típusoknál az az, hogy értékadás jobb oldalának típusát SOSEM határozza meg a bal oldalon álló kifejezés típusa.
Ha valós konstansokat használunk, akkor azok alapértelmezett típusa mindig double, amit az f (float), vagy l (long) utótaggal módosíthatunk.
Nagyon fontos, hogy a típus pontatlansága miatt a == és != operátorokkal nagyon körültekintően kell bánni, könnyen kerülhetünk abba a helyzetbe (különösen nagyon kis valós értékek összehasonlításakor), hogy az elvileg egyenlő valós értékek különböznek egymástól, illetve különböző valós értékek számábrázolása mégis megegyezik.
Példa: háromszögek osztályozása, toleranciával¶
Egy korábbi példához térünk vissza, amelyben háromszögek oldalhosszúságai alapján osztályoztuk a háromszögeket. Éppen ezért most a feladat specifikációját és egyéb elemeket mellőzzük. Fókuszáljunk csak a megvalósításban, amelyben a háromszögek oldalait valós értékek reprezentálják:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 | |
A feladat természetéből adódóan újra és újra össze kell a megoldás során hasonlítani valós számokat.
Erre az eredeti megvalósításban az == összehasonlító műveletet használtuk, azonban ez nem a legjobb választás.
Ezért ezeket az összehasonlításokat lecseréltük úgy, hogyha a két operandus eltérése nem halad meg egy bizonyos pontosságot, akkor az összehasonlításban résztvevő elemeket egyenlőnek feltételezzük.
Mivel ezt az ellenőrzést egy icipicit bonyolultabb felírni, mint egy szimpla összehasonlítást, így a megvalósításban egy makrót alkalmazunk, amely makró tetszőlegesen sokszor és kényelmesen felhasználható.
Nézzük meg ezt részletesebben:
1 | |
Az EQUALS nevű makró két paramétert vár, ezeket hasonlítja össze.
Nyilván nem tudjuk, hogy adott esetben melyik a nagyobb operandus, így vennünk kell a különbség abszolút értékét.
Ezt a célt szolgálja a makró feltételes kifejezése, amit aztán összehasonlítunk egy nagyon kicsi értékkel.
Amennyiben az összehasonlítás eredménye igaz, azaz a két érték igen közel van egymáshoz, az EQUALS kifejezés értéke is igaz lesz.
Mindannyiszor, amikor az EQUALS makrót alkalmazzuk a kódban, a preprocesszor a konkrét paraméterekkel helyettesítve X és Y értékeit, a fenti sort szúrja be.
Valós típusok tárolása¶
Nézzük meg, hogy a gyakorlatban hogyan is történik egy valós szám számítógépes ábrázolása.
Egy valós értéket tároló memóriaterület három részre osztható lebegőpontos számábrázolás esetén: külön ábrázoljuk az előjelbitet, a törtet és az exponenciális kitevőt, mindegyiket fix számú biten tárolva.
A három fogalomból talán elsőre csak az előjelbit szerepe világos mindenkinek.
Ha ennek értéke 0, akkor a szám pozitív, ha értéke 1, akkor a szám negatív.
A tényből, hogy ezt minden esetben ábrázoljuk, világos, hogy miért nem különböztetünk meg valós számok esetében signed és unsigned típusokat, és miért lesz minden valós előjeles típusú.
Amikor egy valós számot ábrázolni akarunk, akkor előtte a számot egy kettes számrendszerbeli 1.m * 2k normál alakra hozzuk. Az m bináris számjegyeit tároljuk a tört részen, a k-nak pedig egy típusfüggő b korrekciós konstanssal megnövelt értékét tároljuk a kitevőnek fenntartott helyen egész számként. Így a tört rész hossza megadja az ábrázolás pontosságát, azaz az értékes számjegyek számát, a kitevő pedig meghatározza az értéktartomány méretét. Nagyon kicsi számokat speciálisan 0.m * 2-b alakban tárolhatunk; ekkor a kitevő minden bitje 0 lesz (-b + b). Ha a kitevő minden bitje 1, két lehetőség van. Ha a tört minden bitje 0, akkor az a végtelent (\(\infty\)) jelöli, minden egyéb eset NaN(="Not a Number") értéket jelöl.
Ha ezeket megérti valaki, akkor megértheti a float és double típusok között rejlő tényleges különbséget is.
A float 32 biten ábrázolja a valós számokat, amelyből 1 bit az előjelé, 8 bit a kitevőjé b = 27-1 = 127 korrekciós értékkel, és a maradék 23 bit a törté.
Ezzel szemben a double 64 biten ábrázolja a valós számokat, amelyből 1 bit az előjelé, 11 bit a kitevőjé b = 210-1 = 1023 értékkel, és a maradék 52 bit a törté.
Azaz a double pontosabb (körülbelül dupla olyan pontos) számábrázolást tesz lehetővé és szélesebb az értéktartománya.
Hogy érthetőbb legyen, nézzük ezt meg piciben, és tegyük fel, hogy csak 8 bites valós számokkal szeretnénk dolgozni, amiből 4 bit lesz a tört, és 3 bit a kitevő b = 22-1 = 3 korrekciós értékkel.
Feladat
Mi az a legkisebb érték, ami ebben az esetben felirható?
Megoldás
Az előjel bit 1-es kell legyen, hiszen nyilván negatív a legkisebb szám.
A kitevő nem lehet csupa 1-es, mert akkor vagy végtelent, vagy NaN-t kapunk, ezért 3 biten a legnagyobb ábrázolható értéket kell vegyük, ami a 1102 = 6. Ez a kitevő értékénél 3-mal több a b korrekciós érték miatt, így a kitevő k = 6-b = 3.
A tört értéke akkor a legnagyobb, ha a tört mindegyik bitje 1-es, azaz a törtrész a 1.11112 számot reprezentálja. Így az ábrázolható lehető legkisebb szám a -1.11112 * 23 = -1111.12 = -15.5
Feladat
Mi a legkisebb "normálisan" (nem csupa 0 kitevővel) ábrázolható pozitív valós szám?
Megoldás
Mivel a legkisebb ilyen számot keressük, a kitevő értéke a lehető legkisebb nem csupa 0, azaz 0012=1 kell legyen, így k = 1-b = -2. A legkisebb értékhez akkor jutunk, ha a tört helyén csupa 0 szerepel. Ez az 1.00002 számot kódolja.
Így kapjuk, hogy a legkisebb "normálisan" ábrázolható pozitív szám az 1.00002 * 2-2 = 0.012 = 1/4.
Feladat
Mi a legkisebb ábrázolható (valóban) pozitív valós szám?
Megoldás
A nagyon kicsi számok ábrázolásakor a kitevő valamennyi bitje 0. Ilyenkor a kitevő mindig a k = 1-b = -2 értéket reprezentálja. Mivel a szám 0.m alakú, így ha a tört minden bitje 0, akkor a számunk értéke is 0. Vagyis, ha a legkisebb pozitív számot szeretnénk ábrázolni, akkor a tört résznek a 0.00012 értéket kell reprezentálnia, tehát m = 0001.
Azaz az ábrázolt szám értéke: 0.00012 * 2-2 = 0.0000012 = 1/64.
Emlékeztetőül: ha a kitevő bitjei mind 1-esek és a tört bitjei mind 0-ák, akkor az előjel bittől függően a mínusz vagy plusz \(\infty\)-t kapjuk. Tulajdonképpen a ±1.00002 * 24 értékkel ábrázoljuk a \(\pm\infty\)-t. Ha a kitevő bitjei mind 1-esek, de a tört bitjei nem csupa nullák, az gyakorlatilag olyan, mintha egy a plusz végtelennél nagyobb (vagy a minusz végtelennél kisebb) számot szeretnénk ábrázolni. Ilyenkor az érték "túlcsordult", ezt nem tekintjük már ábrázolható számnak, azaz NaN értéket kapunk. Végezetül pedig, ha az előjel biten kívül valamennyi bit 0, akkor a ±0.00002 * 2-2 = ±0 értéket ábrázoljuk.
Megjegyzés
A számábrázolás megkülönbözteti a +0 és -0 értékeket, de ezek érték szerint egyenlők.