Hibernate¶
Az előző fejezetben láthattuk, hogy a Spring JDBC hogyan segít a tradicionális JDBC magasabb szintre emelésében. Ennek ellenére még így is rengeteg kódot kellett írnunk a lekérdezéseink előkészítéséhez. Manapság igen népszerű valamilyen ORM technikát alkalmazni annak érdekében, hogy a Java objektumaink és az adatbázis közötti leképezés automatikus módon történjen. Egy ilyen ORM technológiát kínál számunkra a Hibernate.
Fontos megkülönböztetni egymástól a JPA-t (Java Persistent API) és a Hibernate-et. A JPA az ORM technológiában hasonló szerepet játszik, mint a JDBC magában az adatbázis kezelésben, azaz a JPA egy standard interface-t kínál az ORM technológiák számára.
A Hibernate és a JPA ettől függetlenül szinte kéz a kézben jár, de mégis két két opciónk van:
- Közvetlenül a Hibernate API-t használjuk
- JPA-n keresztül használjuk a Hibernate implementációt
Ebben a fejezetben az alap építőkövekre fókuszálunk és megismerjük a Hibernate rendszer belsejének fő alkotóelemeit. Mivel először csak a Hibernate-el foglalkozunk, melyhez H2 DB-t fogunk használni, így a szükséges függőségek a következőek:
1 2 3 4 5 6 7 8 9 10 11 12 | |
Ahogy haladunk előre, akkor áttérünk, majd a Spring Boot JPA támogatásra, ami sok dolgot elrejt előlünk.
SessionFactory¶
A Hibernate egy központi koncepciója a Session interface, melyre a SessionFactory által szerezhetünk referenciát.
A Spring bean támogatást ad arra, hogy a Hibernate SessionFactory-ját konfiguráljuk.
Nézzük is, hogy egy konfigurációs osztályban, hogyan adhatjuk meg a Hibernate beállításait:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | |
Elég sok mindent láthatunk a fenti kódban, így vegyük is azt szépen sorjában.
Először is a konfigurációs osztályon szerepel a @EnableTransactionManagement annotáció, mely engedélyezi a tranzakciós műveletek annotációját (ezekről később lesz szó).
A tranzakciók elvégzéséért a transactionManager felelős, így azt is megadjuk, melynek egy implementációja a HibernateTransactionManager.
Mint, ahogy az látható a sessionFactory bean megadása igen fontos, mivel itt adhatjuk meg a legfontosabb beállításokat:
- Milyen
DataSource-t használjon a Hibernate - Hol keresse a domain modelleket (
setPackagesToScan) - Magára a Hibernate vonatkozó property-k megadása (
setHibernateProperties)
A Hibernate-re vonatkozó beállítások teljes tárházát itt bemutatni túl sok volna. A fent megadottak jelentése:
hibernate.dialect: a lekérdezések SQL dialektusa (H2, mivel most ezt használjuk DB-nek)hibernate.max_fetch_depth: outer join-ok száma mapping esetén (asszociációk mentén, amikor az asszociált objektum is a Hibernate által menedzselt)hibernate.jdbc.fetch_size: A visszakapottResultSet-ből hány elemet olvasson ki egyszerre a rendszer.hibernate.show_sql: SQL műveleteknél az utasításokat logolja a rendszer, ami nagyon jól jön fejlesztés közben
Object Relational Mapping¶
A konfiguráció után neki is kezdhetünk, hogy a létrehozzuk azokat a modelleket, melyeket perzisztálni akarunk, illetve szeretnénk leképezni őket adatbázis táblákká. A mappaléshez kétféleképpen állhatunk hozzá:
- Elkészítjük az objektum modelleket, majd ez alapján legeneráljuk az adatbázis sémát létrehozó szkripteket. Például a hibernate property-k közé elhelyezhetjük a
hibernate.hbm2ddl.autobeállítást, melynek eredményeképpen a legenerált szkripteket a Hibernate automatikusan lefuttatja az adatbázisban, így létrehozza a megfelelő táblákat , azok kapcsolatait, stb. - A másik megközelítés, hogy először az adatbázis oldalon készítjük el a megfelelő struktúrát, majd ez alapján létrehozzuk a POJO-kat is. Ennek a megközelítésnek az előnye, hogy részletesebb tervezést ad a kezünkbe.
A következőkben elkezdjük a modellezést, ehhez a következő adatbázis struktúrát fogjuk felhasználni:
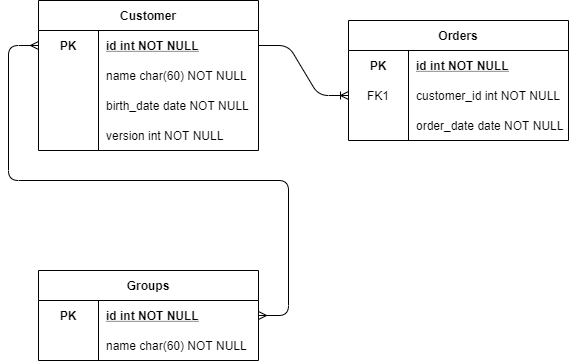
A sémához tartozó DDL:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | |
Figyelem
Figyeljünk oda, hogy ne használjunk olyan táblaneveket, melyből később probléma származik.
Pl.: GROUP, ORDER megzavarhatja a parser-t, mivel beépített kulcsszavak SQL-ben, továbbá ne használjunk USER táblát sem, mert az is valószínűleg foglalt lesz.
Egyszerű mapping¶
Nézzük is meg, hogy a Customer táblának megfelelő Java entitást hogyan hozhatjuk létre:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
Minden Hibernate által menedzselni kíván modell osztályra el kell helyeznünk az @Entity annotációt!
A @Table annotációval megadhatjuk, hogy ennek az entitásnak az adatbázisban milyen tábla felel meg.
A @Data annotációt már ismerjük gyakorlatról (lombok-os annotáció, mely legenerálja a gettereket és settereket, illetve konstruktort, toString-et, equals és hashCode alapértelmezett metódusokat is generál).
Ezután maguk az adattagok következnek, melyeket szintén annotálhatunk.
A fenti példában minden adattagot ellátunk a @Column annotációval, melynek segítségével megadhatjuk, hogy az adott field-et az adatbázisban milyen oszlopnévvel feleltetjük meg.
Fontos
A @Table és a @Column annotációkat el is hagyhatjuk, ha az adatbázisban használt nevek megegyeznek az ezekben magadottakkal.
Vegyük sorra az adattagokon található további annotációkat.
Amennyiben egy osztályt ellátunk egy @Entity annotációval, akkor abban a pillanatban el is kezd vadul jelezni az IDE, hogy bizony kell megadni egy @Id-t is, ami egyértelműen azonosítja az entity-t.
A @Id megadásával igazából az a tábla elsődleges kulcsát (Primary key) adhatjuk meg.
A @GeneratedValue annotációval megadhatjuk azt is, hogy az elsődleges kulcsot milyen módon szeretnénk generáltatni a Hibernate-el.
Az IDENTITY azt jelenti, hogy a beszúrt elemnek maga az adatbázis ad egy egyedi értéket (az indentity egy speciális DB objektum az adatbázisokon belül).
A születési időre megadott @Temporal(TemporalType.DATE) annotáció egy automatikus konverziót jelent.
Java oldalon a java.util.Date típust szeretnénk használni, DB oldalon pedig az adatbázis által biztosított SQL dátumot.
A @Version egy optimista lockolási mechanizmust tesz lehetővé, azaz a konkurrens hozzáférésekkor segíthet.
Amikor update-elni szeretnék egy Customer rekordot, akkor a rendszer megnézni, hogy az adatbázisban található version megegyezik-e az objektum által tárolt version attribútum értékével.
Amennyiben megegyezik, akkor minden rendben és módosíthatom a rekordot.
Amennyiben viszont nem egyezik meg a két szám, az azt jelenti, hogy valaki más is updatelt, ami úgynevezett stale objektumhoz vezet, azaz inkonzisztens állapotot vett fel az objektumunk.
Ilyen esetben a Hibernate dob egy StaleObjectStateException kivételt, melyet a Spring átalakít egy HibernateOptimisticLockingFailureException kivétellé.
Amennyiben használunk ilyen lock-ot az objektumunkon, akkor érdemes int típust használni.
Megjegyzés
Az adattagokra megadott annotációkat a field-ekhez tartozó getterekre is megadjhtjuk.
Feladat
Hozzuk létre a Group és az Order entity-ket is! Egyelőre nem kell semmilyen külső kulcsot hozzáadni a rendszerhez, csak magukra az attribútumokra koncentráljunk!
One-to-Many¶
A Hibernate képes a különféle asszociációk kezelésére is.
Ezek közül az egyik leggyakoribb a One-To-Many, azaz az egy a többhöz kapcsolat.
A példában minden Customer-nek 0 vagy több rendelése (Order) van, azaz itt egy OneToMany kapcsolattal van dolgunk.
Lássuk is, hogy hogyan bővítjük a Customer entity-t, hogy támogassa ezt a kapcsolatot:
1 2 | |
A @OneToMany-nek sok attribútumot adunk át:
mappedBy: AzOrdertáblában megtalálható field, melyhez mappelhetjük a kapcsolatot. Ez csak akkor kell, amikor kétirányúan rögzítjük a kapcsolatot, azaz elérhetjük aCustomer-ből a rendeléseket egy listán keresztül, illetve egy rendelésből is elérhetjük magát a vásárlót. Ha bidirectional kapcsolatot használunk, akkor azOrder-nél is lesz dolgunk (később mutatjuk, hogy mi).cascade: Az ismert kaszkádolt műveleteket lehet megadni. Például egycustormertörlésénél a rendeléseit is töröljük.orphanRemoval: Miután updateljük a rendeléseket, akkor a vevő rendelései közül ki kell törölnünk azokat, amik már nem léteznek.
Ezek után nézzük az Order entitást:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
A kétirányú kapcsolat megvalósításához az Order entitáson a @ManyToOne annotációt kell használnunk, így le tudjuk kérni majd egy rendelés alapján a hozzá tartozó Customer-t is.
Ami, lényeges, hogy az asszociáció megvalósítása tábla szinten a CUSTOMER_ID oszlop segítségével működik (ez a külső kulcs), így meg kell adnunk ezt is, melyet a @JoinColumn annotációval tudjuk megadni.
Több a többhöz kapcsolatok¶
A példában egy vásárló több csoporthoz is tartozhat (0-hoz is), illetve egy csoportba többen is tartozhatnak (tag nélküli is lehet), azaz a két tábla között több a többhöz kapcsolat van.
A több a többhöz kapcsolatok megvalósításához szükség van egy kapcsolótáblára is, mely jelen esetben legye a CUSTOMER_ORDERS!
Nézzük a kódot, mely megvalósítja a fenti funkcionalitást a Customer entitásban:
1 2 3 4 5 6 | |
A Customer-en belül létrehoztunk egy Set-et, melyben tárolni kívánjuk a vásárló csoportjait.
Erre a fieldre elhelyezünk egy @ManyToMany annotációt, mellyel jelezzük, hogy egy több a többhöz kapcsolatról van szó.
Ezután a kapcsolótábla megadása következik a JoinTable megadásával.
Ezen belül megadjuk, hogy jelen táblából, mi lesz a külső kulcs a kapcsolótáblában (@JoinColumns), továbbá megadjuk, hogy a kapcsolat másik oldalán mi lesz a külső kulcs (@InverseJoinColumns).
Ezután meg kell adnunk a kapcsolatot a másik oldalról is, azaz a Group-on belül a következőt kell írnunk:
1 2 3 4 5 6 | |
Látszik, hogy a másik oldalon is teljesen hasonlóan járunk el, de a külső kulcsokat fordítva kell megadnunk.
Hibernate Session interfész¶
Miután előkészítettük a modell osztályainkat, elő kell készítenünk egy DAO objektumot, hogy azon keresztül kommunikálhassunk az adatbázissal. Ennek váza a következő:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
Most nézzük meg, hogy az interface-en milyen metódusokat adunk meg:
1 2 3 4 5 6 7 | |
Látható, hogy semmilyen ördöngősség nincs bennük, egyszerű műveletek melyeket előírunk.
Hibernate Query Language (HQL)¶
A Hibernate rendelkezik egy saját domain specifikus nyelvvel, melyet lekérdezések összerakására használhatunk. Ezeket a HQL utasításokat a Hibernate natív SQL utasításokra fordítja, amikor a tényleges utasítást le kell futtatni az adatbázisban. A HQL nagyon hasonlít az SQL-ra, de gondoljunk arra, hogy itt az objektumokhoz közelien kell hozzáálnunk a lekérdezésekhez. A következőekben néhány példát is megnézünk, mégpedig a fenti interface metódusainak megvalósításán keresztül.
Egyszerű lekérdezések¶
Nézzük meg a findAll megvalósítását.
1 2 3 4 5 6 7 8 9 | |
A SessionFactory.getCurrentSession() segítségével referenciát szerezhetünk a Session objektumra.
A session objektumon keresztül lehetőséget kapunk tetszőleges lekérdezés összerakására, melyben HQL-t használhatunk.
A fent megadott HQL segítségével az összes Customer-t lekérdezhetjük a táblából.
Alternatívaként írhattuk volna a következőt is: select c from Customer c
Egy-egy metódusra megadhatjuk a @Transactional annotációt is, mely szabályozhatjuk a tranzakciókezelés szabályait.
Jelen esetben megmondjuk, hogy a findAll csupán olvasni szeretne a DB-ből.
Amennyiben a lekérdezést később valaki átírja és az adatot is módosítana, akkor kivételt kapunk.
A readOnly attribútum beállítása nyilván teljesítménynövekedést is eredményez(het).
A fenti kód futtatásakor kapni fogunk egy org.hibernate.LazyInitializationException-t: failed to lazily initialize a collection of role: ... could not initialize proxy - no Session.
Ez a hiba amiatt keletkezik, mert a kapcsolatok mentén lustán kérjük le az adatokat, azaz a Hibernate nem kapcsolja az asszociált táblákat.
Ezt performancia miatt teszi így a Hibernate.
Ahhoz, hogy a Hibernate lekérje az asszociált adatokat is két opciónk van:
- megadjuk a fetchMode-ot EAGER-re. Példa:
@ManyToMany(fetch=FetchType.EAGER) - Rávenni a Hibernate-et, hogy akkor kérdezze le az asszociációkat, amikor szükség van rá:
Criterialekérdezés ->Criteria.setFetchMmode()(ezt csak később nézzük meg). Ugyanerre képesek lehetünk a@NamedQueryhasználatával.
Vegyük azt a lekérdezést, amikor a rendelésekkel együtt szeretnénk lekérdezni a vásárlókat.
Ehhez a következőt csinálhatjuk NamedQuery használatával:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
Amit nagyon fontos észrevenni az a left join fetch, ami azt parancsolja a Hibernate-nek, hogy a EAGER módon kérje le az asszociációk mentén a többi entitást is.
A @NamedQuery-ket a következőképpen használhatjuk fel a Dao-ban:
1 2 3 4 5 | |
A Session-ön keresztül használhatjuk a nevesített lekérdezéseket a getNamedQuery() metódussal.
Annak érdekében, hogy lássunk paraméterezésre is példát a nevesített lekérdezéseknél, írjuk meg a findById lekérdezést!
1 2 3 4 | |
A nevesített lekérdezésben használhatunk nevesített paramétereket (jelen esetben a :id).
Ezután a felhasználás helyén meg kell adnunk a paraméter értékét a setParameter használatával, illetve gondoskodnunk kell arról, hogy csak egy objektumot adjunk vissza!
1 2 3 4 | |
Több paraméter esetén használhatjuk a setParameterList() vagy a setParameters() metódusokat.
Ezeken felül vannak még haladóbb lekérdezési technikák, de ezeket csak később nézzük majd meg.
Hibernate használatával az új objektumaink elmentése végtelenül egyszerű:
1 2 3 4 5 | |
A fenti példában a Session-ön meghívjuk a saveOrUpdate metódust, mely az egyedi azonosító alapján eldönti, hogy új elemet kell beszúrni vagy egy létezőt updatelni.
JDBC-ben sokkal nagyobb munkába került, hogy az új elemnek a kulcsát visszakapjuk, jelen helyzetben viszont az átadott objektum adattagjait beállítja a rendszer, így az id-t is.
Az objektumot visszaadni ezért célszerű.
A mentéshez hasonló egyszerűséggel törölhetünk is, ha a Session-ön meghívjuk a delete() metódust.
Táblák generálása¶
Általánosan alkalmazott technika, hogy először megírjuk az entity osztályokat és aztán ebből generáljuk le a táblákat.
Ehhez a Hibernate property-k közé hozzá kell adnunk a következőt: hibernate.hbm2ddl.auto!
Ez a property több értéket is felvehet:
create: Első indításkor ezt használjuk, így az entity osztályok alapján létrejön az összes tábla.update: Acreateután, amennyiben minden megfelelően létrejött, akkor a property értékét átállítjukupdate-re, mely megtartja az eredeti táblákat és a bennük található adatokat is, viszont bővíteni is képesek vagyunk a segítségével (új tábla, új oszlop, stb.).create-drop: Tesztelés közben általában egy in-memory DB-t használunk a tesztek futtatásakor, melyet a folyamat elején inicializálunk, majd a végén eldobunk. Ehhez használhatjuk acreate-dropproperty beállítást.none: Amennyiben nem szeretnénk az entitások alapján semmilyen műveletet sem eredményezni az adatbázison, akkor használhatjuk anoneértéket.