Linux IPC - I.¶
A gyakorlat anyaga¶
A legegyszerűbben úgy kerülhetünk párhuzamos programozási környezetbe, ha veszünk egy hagyományos szekvenciális programozási nyelvet és kiegészítjük párhuzamos konstrukciókkal, pl.: a C nyelv + Linux rendszerhívások.
A párhuzamos folyamatok közötti kommunikáció (IPC - Inter Process Communication) kifejezetten azokra a mechanizmusokra utal, amelyeket az operációs rendszer biztosít a folyamatok számára a közös adatok kezeléséhez. Ezzel a módszerrel akár közös memóriás, akár osztott memóriás modellben is programozhatunk.
A fork() hívás¶
A fork() hívás szolgál arra, hogy egy új folyamatot hozzunk létre a hívó folyamat duplikálásával. Ez nem a teljes hivó folyamatra vonatkozik a kezdetektől, hanem ami a fork() hívás helyétől kezdve fogja ugyanazt a programot futtatni. Erről a legegyszerűbben megbizonyosodhatunk, ha az alább található fork() hívásunk elé szintén elhelyezünk egy tetszőleges kiíratást (ez csak egyszer fog kiírásra kerülni).
Egy folyamatot bizonyos ideig szüneteltetni tudunk a sleep(..) függvény segítségével, amely paraméterben a szüneteltés (altatás) hosszát várja másodpercben. Egészítsük ki a példánkat elegendően hosszú altatással a fork() hívás előtt és után is, majd futtasuk a programot. Nyissunk egy terminált, és a ps -ao pid,ppid,psr,comm utasítás segítségével bizonyosodjunk meg róla, hogy a folyamat valóban megduplázódott (akár az utasítás többszöri kiadásával a terminálban).
1 2 3 4 5 6 7 | |
Egészítsük ki a programunkat több fork() hívással. Az egymást követő n db fork() hívás 2^n db folyamatot eredményez. A fork és a sleep függvényeket használatához szükség lesz még az <unistd.h> header fájlra, ezen kívül a standard I/O műveletekre van még szükségünk (<stdio.h>).
Folyamatok azonosítói¶
Előző példában megnéztük hogy tudunk új processzt létrehozni, azonban ezeket a processzeket szeretnék azonosítani is valamilyen módon, illetve a folyamatok között alá- és fölérendeltségi viszonyt is meg szeretnék állapítani. Egy fork() hívás esetén tehát megkülönbözhetünk szülő és gyerek folyamatot: a függvényhívás visszatérési értéke 0 lesz gyerek folyamat esetén, nagyobb, mint 0 lesz szülő processz esetén, egyéb esetben pedig hiba történt a folyamat létrehozásakor. A pid_t típus egy signed int típust jelent, ami megegyezik a GNU C library esetén az int típussal.
Mintaprogramunk tartalmazza még a gyerek folyamatok esetén alkalmazandó _exit(EXIT_SUCCESS) és a szülő folyamat esetén alkalmazandó exit(EXIT_SUCCESS) függvényhívásokat (<stdlib.h>), amellyel megelőzhetjük, a standard I/O csatornák többszöri lezáródását, mielőtt a programunk terminálna.
Fontos megjegyezni továbbá, hogy megkülönböztetjük a processzek azonosítóit a C programon belül és a folyamatok Linux rendszerbeli azonosítóit. Hogy lekérjük az adott folyamat azonosítóját, használjuk a getpid() függvényt, a folyamat szülőjéhez tartozó azonosító lekéréséhez pedig a getppid() függvényt. További érdekesség, hogy a C programon belül a szülő szál a gyerek folyamat Linux rendszerbeli azonosítóját kapja meg.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | |
Egészítsük ki a programot még egy fork() hívással és hasonlítsuk össze a létrejött 4 folyamat C programbeli, illetve a Linux rendszerbeli azonosítóit (getpid(),getppid()).
Virtuális memória¶
Ahhoz, hogy közös memóriát tudjunk létrehozni, további függvényhívásokra lesz majd szükség. Most nézzük meg, hogyan reagál az alábbi program, ha egy közösnek tűnő változót mindkét folyamat módosítja:
1 2 3 4 5 6 7 8 9 10 11 | |
Ahogy látjuk, a két folyamat egymástól függetlenül módosítja a változó értékétg. Amikor a fork() hívás megtörténik, akkor a szülőhöz tartozó memórialapról másolat készül, amit a gyerek folyamat örököl. Az is előfordulhat, hogy a függvényhíváskor nem történik másolat, hanem a szülő és a gyerek folyamat megosztja egymás között a memórialapot és csupán akkor készül másolat, ha valamelyik folyamat módosítaná a memórialapot (lásd Copy-on-write).
Másfelelől ha kiegészítjük a programunkat a változó memóriacímének kiíratásával, láthatjuk, hogy a két memóriacím megegyezik. Ez azonban nem jelenti azt, hogy a szülő és a gyerek folyamathoz tartozó változó ugyanazon a fizikai pozícióban van eltárolva, hanem a modern számítógépek virtuális memóriacímzése végett egyezik meg a memóriacím (azaz minden folyamat memóriája ugyanazon a virtuális címen kezdődik). Ezt szintén leellenőrizhetjük, ha az x változó címét kiiratjuk a programban.
Folyamatok ábrázolása¶
A következő példában gondoljuk végig hányszor kerül kiíratásra a "Hello world!" üzenet. Továbbra is igaz, hogy n fork() hívás esetén 2^n folyamat jön létre, azonban gondoljuk végig a függvényhívások és a kiíratások sorrendjét (összehasonlítva az első kikommentezett blokkal).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | |
Az egymást követő fork() hívások könnyen ábrázolhatóak egy gráfként, ahol a csomópontokban az egyes folyamatok szerepelnek, például a fenti programban található második kikommentezett blokk ábrázolását és kimenetét mutatja be a következő ábra (draw.io forrás).
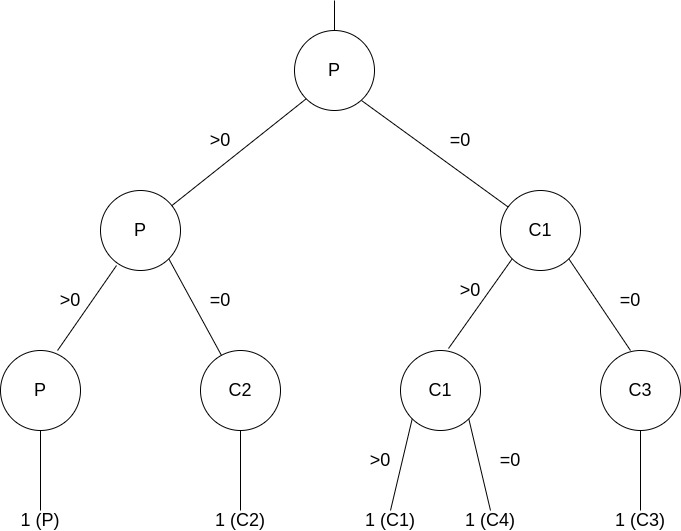
Folyamatok bevárása és számuk korlátozása¶
Bizonyos esetekben szükség van arra, hogy az egyes folyamatok bevárják egymást, például ha egy adott problémát több részfeladatra pontottunk és a részfeladatokat feldolgozó (al)folyamatok különböző ideig számolnak, majd a részeredményeket összegezni szeretnék a fő folyamatban. Erre szolgál nekünk a wait(NULL) függvényünk (sys/wait.h), amellyel képes a programunk egy folyamatot bevárni (nem tudjuk megmondani, melyiket). Lehetőség van egy konkrét folyamatot is bevárni a waitpid(..) függvénnyel (lásd Kapcsolódó linkek) További megkötés, hogy csak a szülő folyamat képes bevárni a gyerek folyamatokat a wait(..) segítségével. A szülő folyamat addig lesz blokkolva, amíg a gyermekfolyamat nem küld vissza egy kilépési állapotot az operációs rendszernek, a vezérlés aztán visszakerül a szülő folyamathoz.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | |
Bizonyos esetben szükség van arra, hogy egy szülő folyamat bizonyos számú gyerek folyamatot hozzon létre, azaz szeretnék megakadályozni, hogy a gyerek folyamatok további folyamatok őseként viselkedjen. Ezt a legkönyebben például úgy érthetjük el, hogy a gyerek folyamat esetén a ciklusból a break utasítás segítségével kilépünk.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | |
Végezetül az előző példát egészítsük ki azzal, hogy a gyerekfolyamatok szüneteltetést a szülő folyamat bevárja. Az n db létrehozott gyerek folyamat bevárásához n db wait(NULL) utasítás szükséges. Ebben a példában a gyerek folyamatok 3 másodpercig vannak szüneteltetve, azonban érdemes végiggondolni, hogy hogyan tudnánk különböző ideig szüneteltetni az egyes folyamatokat. Világosan látszik, hogy önmagában a "hagyományos módon történő" randomszám generálás nem jó megoldás, hiszen az egyes folyamatok ugyanabból a seed-ból indíthatják a pszeudorandom szám generálást (emlékeztetőül: szülő memórialapjának lemásolása, megegyező változókészletek). Azonban kombinálhatjuk a random szám generálását egy egyedi azonosítóval, például minden folyamat rendelkezik egy Linux rendszerbeli egyedi azonosítóval (getpid()).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | |
Gyakorló feladat¶
Mi az alábbi program kimenete és miért? Az indoklás egy lehetséges módja a folyamatok ábrázolása a korábbi példához hasonlóan (pl. papíron olvasható rajzzal, vagy draw.io-n). Lehetőség szerint egységes jelölést használjunk (pl. a bal részfa jelölje mindig >0 esetet, a jobb részfa pedig a =0 esetet).
1 2 3 4 5 6 7 8 9 10 11 | |